Flink流处理应用在IDEA中的执行流程分析
Flink流式计算的核心概念就是将数据从输入流一个个传递给operator进行链式处理 , 最后交给输出流的过程 。 对数据的每一次处理在逻辑上成为一个operator(算子) 。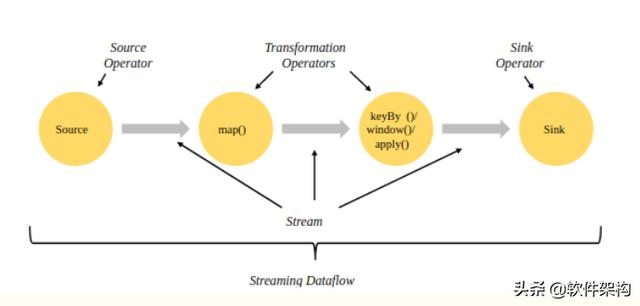 文章插图
文章插图
Flink经典示例WordCount流处理应用-整个执行流程如下图所示: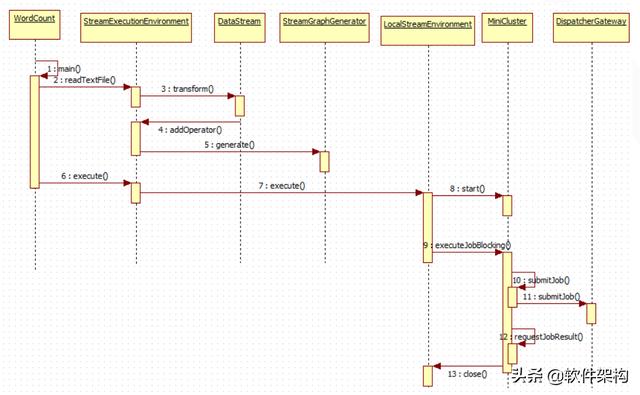 文章插图
文章插图
第1~4步:main方法读取文件 , 增加算子;
第5步:产生StreamGraph , 从而可以得到JobGraph , 即将Stream程序转换成JobGraph;
第6~8步:LocalEnvironment 是本地执行任务的环境 , 负责启动MiniCluster , 在本地执行Flink任务 。 MiniCluster可以看做是内嵌的Flink运行时环境 , 所有的组件都在独立的本地线程中运行 。 MiniCluster的启动入口在LocalStreamEnvironment#execute(jobName)中 。
第9~12步:执行job;
【Flink流处理应用在IDEA中的执行流程分析】第13步:关闭执行流程;
- 赵明|赵明:华为空出的市场理应被国产品牌瓜分的看法非常幼稚
- 程一笑|快手理应自信
- 苹果|又搞大动作?苹果即将又发新品,就在下周这些产品理应出现
- 高空抛物|云市场能力服务化,华为云联合上海打造数字治理应用市场
- 数据库|Flink + Iceberg + 对象存储,构建数据湖方案
- 产品经理应如何获取和使用客户反馈
- 极客网FromGeek |2021健身场馆管理系统排行“出炉”?这家系统排名理应靠前
- 科技助力打造方便温馨之城!青岛38个城市管理应用场景开放
- “先富起来”的互联网企业理应承担战略科技崛起梦想
- 中国网科技|微信发布第三方违规导流处理公示:已对知乎、好看视频等外链进行限制