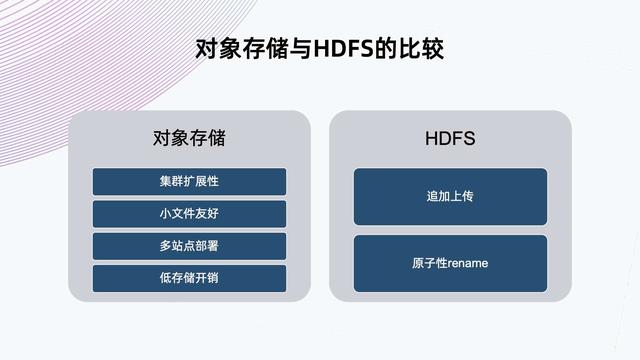
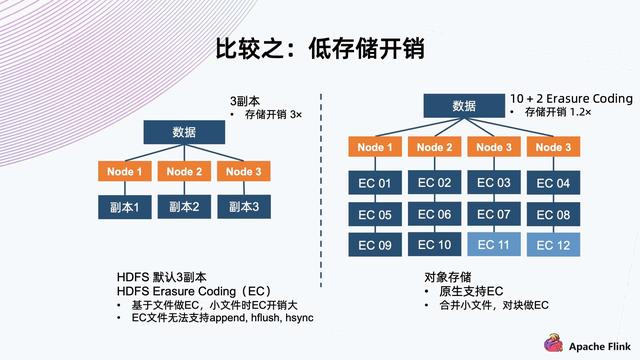
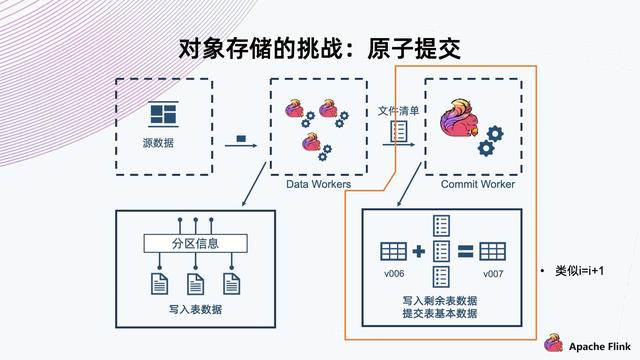
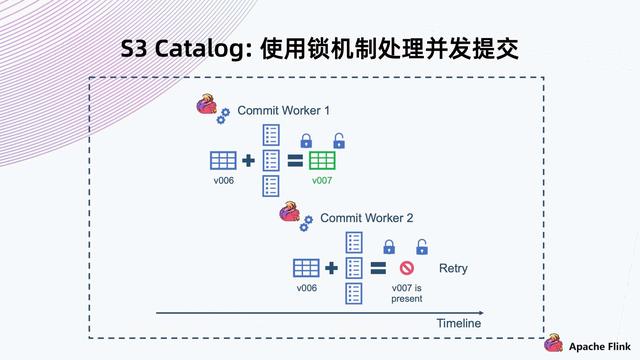
文章图片
文章图片
文章图片
文章图片
文章图片

文章图片
文章图片

文章图片
文章图片
文章图片
文章图片
文章图片
本文整理自 Dell 科技集团高级软件研发经理孙伟在 4 月 17 日 上海站 Flink Meetup 分享的《Iceberg 和对象存储构建数据湖方案》 , 文章内容为:
1.数据湖和 Iceberg 简介
2.对象存储支撑 Iceberg 数据湖
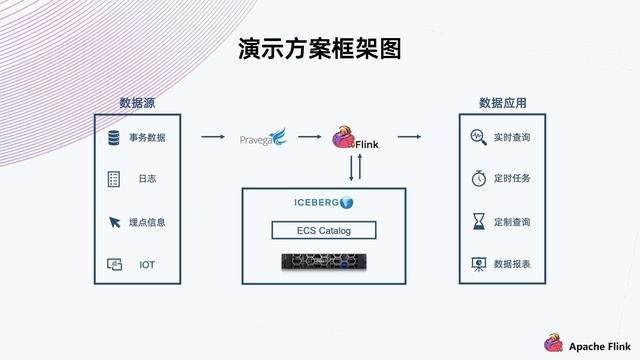
3.演示方案
4.存储优化的一些思考
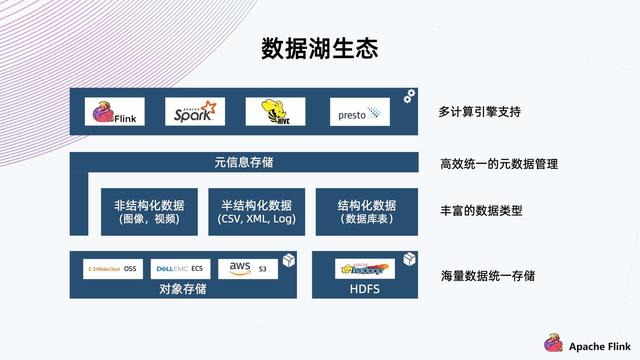
一、数据湖和 Iceberg 简介 1. 数据湖生态
如上图所示 , 对于一个成熟的数据湖生态而言:
首先我们认为它底下应具备海量存储的能力 , 常见的有对象存储 , 公有云存储以及 HDFS; 在这之上 , 也需要支持丰富的数据类型 , 包括非结构化的图像视频 , 半结构化的 CSV、XML、Log , 以及结构化的数据库表; 除此之外 , 需要高效统一的元数据管理 , 使得计算引擎可以方便地索引到各种类型数据来做分析 。 最后 , 我们需要支持丰富的计算引擎 , 包括 Flink、Spark、Hive、Presto 等 , 从而方便对接企业中已有的一些应用架构 。 2. 结构化数据在数据湖上的应用场景
上图为一个典型的数据湖上的应用场景 。
数据源上可能会有各种数据 , 不同的数据源和不同格式 。 比如说事物数据 , 日志 , 埋点信息 , IOT 等 。 这些数据经过一些流然后进入计算平台 , 这个时候它需要一个结构化的方案 , 把数据组织放到一个存储平台上 , 然后供后端的数据应用进行实时或者定时的查询 。
这样的数据库方案它需要具备哪些特征呢?
首先 , 可以看到数据源的类型很多 , 因此需要支持比较丰富的数据 Schema 的组织; 其次 , 它在注入的过程中要支撑实时的数据查询 , 所以需要 ACID 的保证 , 确保不会读到一些还没写完的中间状态的脏数据; 最后 , 例如日志这些有可能临时需要改个格式 , 或者加一列 。 类似这种情况 , 需要避免像传统的数仓一样 , 可能要把所有的数据重新提出来写一遍 , 重新注入到存储;而是需要一个轻量级的解决方案来达成需求 。 Iceberg 数据库的定位就在于实现这样的功能 , 于上对接计算平台 , 于下对接存储平台 。
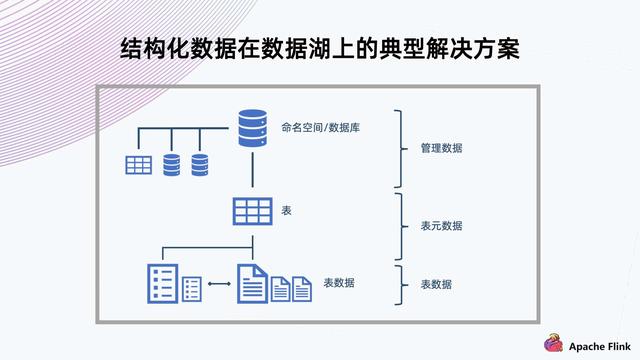
3. 结构化数据在数据湖上的典型解决方案
对于数据结构化组织 , 典型的解决方式是用数据库传统的组织方式 。
如上图所示 , 上方有命名空间 , 数据库表的隔离;中间有多个表 , 可以提供多种数据 Schema 的保存;底下会放数据 , 表格需要提供 ACID 的特性 , 也支持局部 Schema 的演进 。
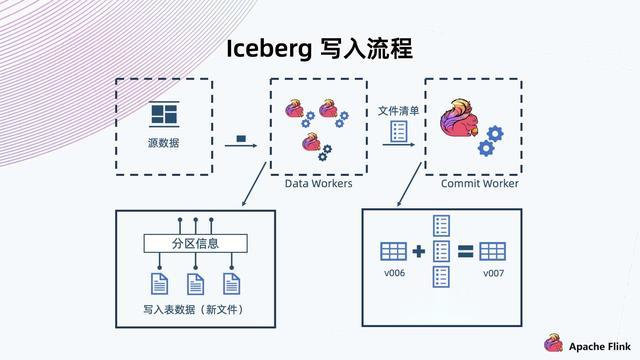
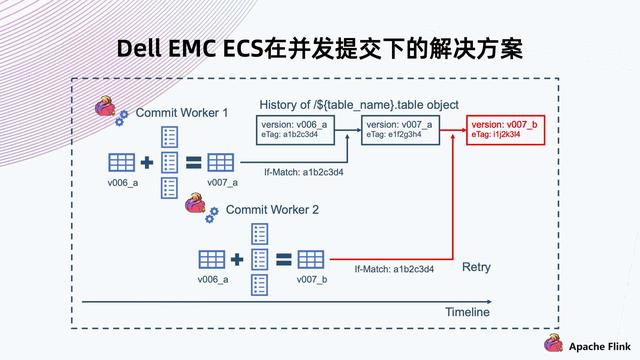
【数据库|Flink + Iceberg + 对象存储,构建数据湖方案】4. Iceberg 表数据组织架构
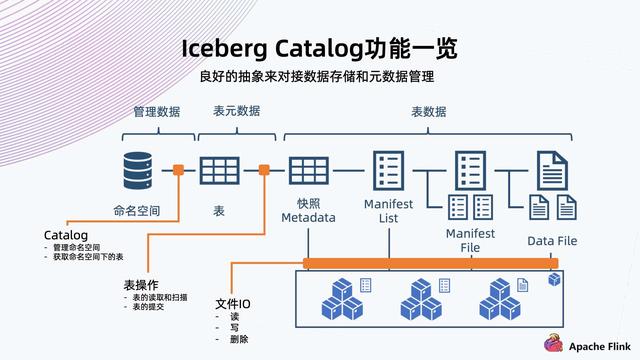
快照 Metadata:表格 Schema、Partition、Partition spec、Manifest List 路径、当前快照等 。 Manifest List:Manifest File 路径及其 Partition , 数据文件统计信息 。 Manifest File:Data File 路径及其每列数据上下边界 。 Data File:实际表内容数据 , 以 Parque , ORC , Avro 等格式组织 。 接下来具体看一下 Iceberg 是如何将数据组织起来的 。 如上图所示:
- 数据库|提前三天自动续费,这合理吗?
- 微软|打工人必备技能!django查询数据库操作合集!
- 安卓|django怎么连接数据库?你知道吗?
- 数据库|不惜1.88亿置地造零件 华为做“中国博世”实锤了?
- 数据库|Jedis操作Redis数据库(八)
- 数据库|有没有适合学生的品牌蓝牙耳机?学生党最爱的平价蓝牙耳机推荐
- 一个 Babelfish ,看懂云数据库的发展方向
- 研发中心|36氪首发|「四维纵横」完成1亿人民币A轮融资,打造超融合时序数据库
- 数据库|苹果VR头盔将拥有Mac级别的计算能力,将于2022年第四季度推出
- 数据库|django怎么连接数据库?你知道吗?