综述|计算机视觉中的注意力机制( 六 )
- 首先对输入的 feature map X 进行线性映射(通过1x1卷积 , 来压缩通道数) , 然后得到 θ,?,g 特征
- 通过reshape操作 , 强行合并上述的三个特征除通道数外的维度 , 然后对 进行矩阵点乘操作 , 得到类似协方差矩阵的东西(这个过程很重要 , 计算出特征中的自相关性 , 即得到每帧中每个像素对其他所有帧所有像素的关系)
- 然后对自相关特征 以列or以行(具体看矩阵 g 的形式而定) 进行 Softmax 操作 , 得到0~1的weights , 这里就是我们需要的 Self-attention 系数
- 最后将 attention系数 , 对应乘回特征矩阵g中 , 然后再上扩channel 数 , 与原输入feature map X残差
Github地址:
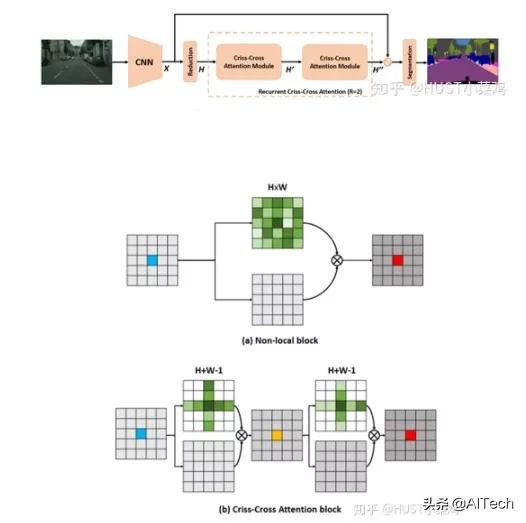
本篇文章的亮点在于用了巧妙的方法减少了参数量 。 在上面的DANet中 , attention map计算的是所有像素与所有像素之间的相似性 , 空间复杂度为(HxW)x(HxW) , 而本文采用了criss-cross思想 , 只计算每个像素与其同行同列即十字上的像素的相似性 , 通过进行循环(两次相同操作) , 间接计算到每个像素与每个像素的相似性 , 将空间复杂度降为(HxW)x(H+W-1)
 文章插图
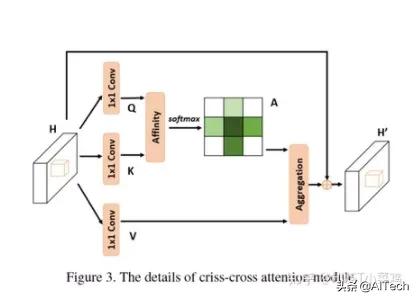
文章插图在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘 , 计算相似度 。 和non-local的方法相比极大的降低了计算量 , 同时采用二阶注意力 , 能够从所有像素中获取全图像的上下文信息 , 以生成具有密集且丰富的上下文信息的新特征图 。 在计算矩阵相乘时 , 每个像素只抽取特征图中对应十字位置的像素进行点乘 , 计算相似度 。
 文章插图
文章插图def _check_contiguous(*args):
if not all([mod is None or mod.is_contiguous() for mod in args]):
raise ValueError("Non-contiguous input")
class CA_Weight(autograd.Function):
@staticmethod
def forward(ctx, t, f):
# Save context
n, c, h, w = t.size()
size = (n, h+w-1, h, w)
weight = torch.zeros(size, dtype=t.dtype, layout=t.layout, device=t.device)
_ext.ca_forward_cuda(t, f, weight)
# Output
ctx.save_for_backward(t, f)
return weight
@staticmethod
@once_differentiable
def backward(ctx, dw):
t, f = ctx.saved_tensors
dt = torch.zeros_like(t)
df = torch.zeros_like(f)
_ext.ca_backward_cuda(dw.contiguous(), t, f, dt, df)
_check_contiguous(dt, df)
return dt, df
class CA_Map(autograd.Function):
@staticmethod
def forward(ctx, weight, g):
# Save context
out = torch.zeros_like(g)
_ext.ca_map_forward_cuda(weight, g, out)
# Output
ctx.save_for_backward(weight, g)
return out
@staticmethod
@once_differentiable
def backward(ctx, dout):
weight, g = ctx.saved_tensors
dw = torch.zeros_like(weight)
dg = torch.zeros_like(g)
_ext.ca_map_backward_cuda(dout.contiguous(), weight, g, dw, dg)
_check_contiguous(dw, dg)
return dw, dg
ca_weight = CA_Weight.apply
ca_map = CA_Map.apply
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self,in_dim):
super(CrissCrossAttention,self).__init__()
self.chanel_in = in_dim
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self,x):
proj_query = self.query_conv(x)
proj_key = self.key_conv(x)
proj_value = http://kandian.youth.cn/index/self.value_conv(x)
energy = ca_weight(proj_query, proj_key)
attention = F.softmax(energy, 1)
out = ca_map(attention, proj_value)
out = self.gamma*out + x
return out
__all__ = ["CrissCrossAttention", "ca_weight", "ca_map"]
四、强注意力(hard attention)0/1问题 , 哪些被attention , 哪些不被attention 。 更加关注点 , 图像中的每个点都可能延伸出注意力 , 同时强注意力是一个随机预测的过程 , 更加强调动态变化 , 并且是不可微 , 所以训练过程往往通过增强学习 。
参考资料
Gapeng:Non-local neural networks
NX-8MAA09148HY:双注意力网络 , 是丰富了还是牵强了attention?
作者丨HUST小菜鸡@知乎
来源丨
本文仅作学术分享 , 著作权归作者所有 , 如有侵权 , 请联系后台作删文处理 。
- 计算机学科|机器视觉系统是什么
- 视觉|首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金
- 检测|机器视觉检测解决方案商“鼎纳自动化”完成B轮亿元融资
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- 顶尖的计算机专家,会采用何种方式来看待这个世界
- 吉林大学TARS-GO战队视觉代码
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- NCT|NCT获IEEE计算机协会和麻省理工科技评论权威认证
- 首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金