综述|计算机视觉中的注意力机制( 四 )
)
def _get_activation_fn(activation):
"""Return an activation function given a string"""
if activation == "relu":
return F.relu
if activation == "gelu":
return F.gelu
if activation == "glu":
return F.glu
raise RuntimeError(F"activation should be relu/gelu, not {activation}.")
三、软注意力(soft-attention)软注意力是一个[0,1]间的连续分布问题 , 更加关注区域或者通道 , 软注意力是确定性注意力 , 学习完成后可以通过网络生成 , 并且是可微的 , 可以通过神经网络计算出梯度并且可以前向传播和后向反馈来学习得到注意力的权重 。
1、空间域注意力(spatial transformer network)论文地址:
GitHub地址:
空间区域注意力可以理解为让神经网络在看哪里 。 通过注意力机制 , 将原始图片中的空间信息变换到另一个空间中并保留了关键信息 , 在很多现有的方法中都有使用这种网络 , 自己接触过的一个就是ALPHA Pose 。 spatial transformer其实就是注意力机制的实现 , 因为训练出的spatial transformer能够找出图片信息中需要被关注的区域 , 同时这个transformer又能够具有旋转、缩放变换的功能 , 这样图片局部的重要信息能够通过变换而被框盒提取出来 。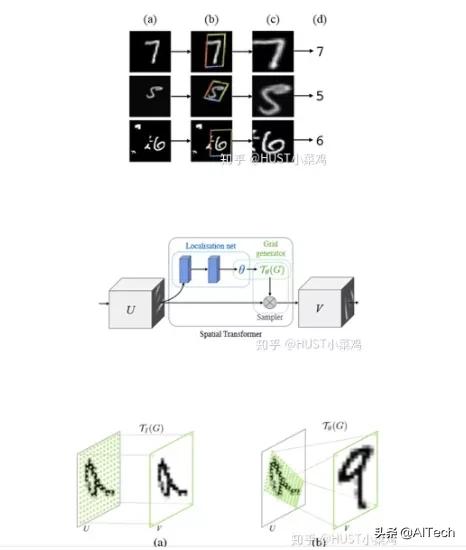 文章插图
文章插图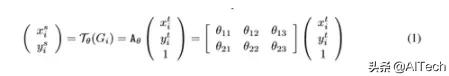 文章插图
文章插图
主要在于空间变换矩阵的学习
class STN(Module):
def __init__(self, layout = 'BHWD'):
super(STN, self).__init__()
if layout == 'BHWD':
self.f = STNFunction()
else:
self.f = STNFunctionBCHW()
def forward(self, input1, input2):
return self.f(input1, input2)
class STNFunction(Function):
def forward(self, input1, input2):
self.input1 = input1
self.input2 = input2
self.device_c = ffi.new("int *")
output = torch.zeros(input1.size()[0], input2.size()[1], input2.size()[2], input1.size()[3])
#print('decice %d' % torch.cuda.current_device())
if input1.is_cuda:
self.device = torch.cuda.current_device()
else:
self.device = -1
self.device_c[0] = self.device
if not input1.is_cuda:
my_lib.BilinearSamplerBHWD_updateOutput(input1, input2, output)
else:
output = output.cuda(self.device)
my_lib.BilinearSamplerBHWD_updateOutput_cuda(input1, input2, output, self.device_c)
return output
def backward(self, grad_output):
grad_input1 = torch.zeros(self.input1.size())
grad_input2 = torch.zeros(self.input2.size())
#print('backward decice %d' % self.device)
if not grad_output.is_cuda:
my_lib.BilinearSamplerBHWD_updateGradInput(self.input1, self.input2, grad_input1, grad_input2, grad_output)
else:
grad_input1 = grad_input1.cuda(self.device)
grad_input2 = grad_input2.cuda(self.device)
my_lib.BilinearSamplerBHWD_updateGradInput_cuda(self.input1, self.input2, grad_input1, grad_input2, grad_output, self.device_c)
return grad_input1, grad_input2
2、通道注意力(Channel Attention , CA)通道注意力可以理解为让神经网络在看什么 , 典型的代表是SENet 。 卷积网络的每一层都有好多卷积核 , 每个卷积核对应一个特征通道 , 相对于空间注意力机制 , 通道注意力在于分配各个卷积通道之间的资源 , 分配粒度上比前者大了一个级别 。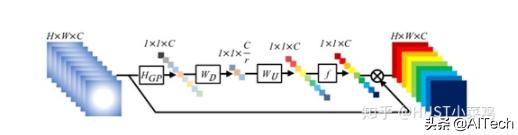 文章插图
文章插图
论文:Squeeze-and-Excitation Networks()
GitHub地址:
Squeeze操作:将各通道的全局空间特征作为该通道的表示 , 使用全局平均池化生成各通道的统计量
Excitation操作:学习各通道的依赖程度 , 并根据依赖程度对不同的特征图进行调整 , 得到最后的输出 , 需要考察各通道的依赖程度
整体的结构如图所示: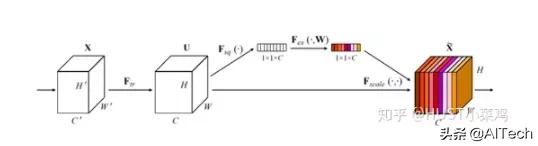 文章插图
文章插图
卷积层的输出并没有考虑对各通道的依赖 , SEBlock的目的在于然根网络选择性的增强信息量最大的特征 , 是的后期处理充分利用这些特征并抑制无用的特征 。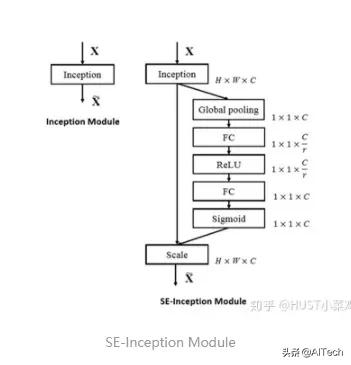 文章插图
文章插图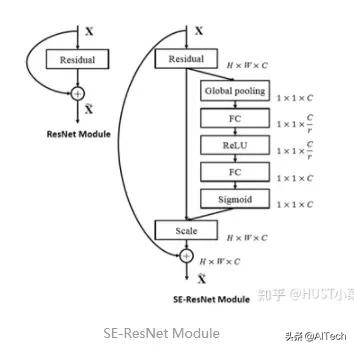 文章插图
文章插图
- 将输入特征进行 Global avgpooling , 得到1×1×Channel
- 然后bottleneck特征交互一下 , 先压缩channel数 , 再重构回channel数
- 最后接个sigmoid , 生成channel间0~1的attention weights , 最后scale乘回原输入特征
class SEBasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
- 计算机学科|机器视觉系统是什么
- 视觉|首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金
- 检测|机器视觉检测解决方案商“鼎纳自动化”完成B轮亿元融资
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- 顶尖的计算机专家,会采用何种方式来看待这个世界
- 吉林大学TARS-GO战队视觉代码
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- NCT|NCT获IEEE计算机协会和麻省理工科技评论权威认证
- 首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金