文章图片
在Channel 9上 , 有一位观众提到:”我实在没想到数据类型的长度变化之后 , 会对各类应用程序产生如此大的影响 。 ” 于是 , 我决定是时候写一篇文章 , 来介绍下Win64下的数据模型了 。
Win64开发团队选择了LLP64数据模型 , 在这个数据模型中 , 所有的整数类型都维持32位的长度 , 仅仅是指针类型扩展到了64位 , 这是为啥呢?
除了官方技术文档中给出的一系列理由之外 , 还有另外一个原因:将数据模型选定为LLP64 , 可以避免对一些持久化格式所产生的不兼容性破坏 。
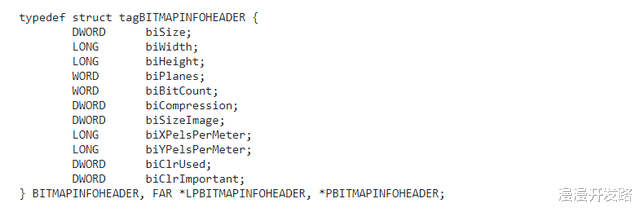
举个例子 , 一个位图(Bitmap)的头部使用了如下图所示的结构体进行定义:
【芯片|为什么Win64开发团队选择LLP64数据模型?】
如果一个LONG类型从32位扩展到64位 , 则对于一个64位程序来说 , 它将不可能使用这一数据结构对一个位图文件进行解析 。
对于持久化格式 , 其不仅限于文件 。 还有诸如RPC和DCOM , 注册表中的二进制块数据 , 另外 , 共享内存也可以用来在进程间进行数据传输 。 如果源地址和目标地址使用了不同的位模式 , 则对整数类型长度的变更 , 会导致格式的不一致 , 从而引发传输失败 。
另外请注意了 , 对于这些进程间的数据通信场景 , 我们无须担心指针的长度变化 , 因为没有人会在跨越进程边界来传输指针值 。 单独的进程地址空间意味着某个指针值对于另外的进程来说是没有任何意义的 , 甚至贸然使用它会导致内存读写异常 。 既然这样 , 那就完全没有必要来共享这个指针值了 。
总结有一段时间 , 我经常花费脑力来记忆各种整数类型(int short long long long)的长度 , 但又老是记不住 。
而今 , 我明白了:别瞎折腾 , 咱们写的程序99.999%基本都可以靠int解决问题 。
“还是int对我们好 。 ”
最后Raymond Chen的《The Old New Thing》是我非常喜欢的博客之一 , 里面有很多关于Windows的小知识 , 对于广大Windows平台开发者来说 , 确实十分有帮助 。
本文来自:《Why did the Win64 team choose the LLP64 model?》
- 芯片|元宇宙概念火爆,虚拟地产是否值得投资
- 小米科技|小米芯片是自研吗?之前深信不疑,现在我却犯了嘀咕
- thread|同为安卓软件,在国内流氓,在国外却老实了,为什么?
- 芯片|美国用芯片制裁俄罗斯,竟然遭到俄罗斯“反杀”,仅有的库存只能维持几天
- 芯片|4月底5款新机发布:女生自拍机、游戏手机、影像手机、智能电视
- 芯片|“互联网教父”张朝阳 :坐拥亿万资产却沉迷当物理老师,57岁仍未婚
- 发达国家|老美用110v电压,我们为什么选择220v?内行人才懂原因
- 华为|华为Mate40Pro官方降价,麒麟9000芯片加持,还用抢吗?
- 芯片|做自研芯片有多难?这已经不是有钱就够了
- vivo x80|5499元跌至3599元,A14芯片+5.4英寸,三千档的苹果手机,不香吗