python写一个豆瓣短评通用爬虫并可视化分析
前言在本人上的一门课中 , 老师对每个小组有个任务要求 , 介绍和完成一个小模块、工具知识的使用 。 然而我所在的组刚好遇到的是python爬虫的小课题 。
心想这不是很简单嘛 , 搞啥呢?想着去搞新的时间精力可能不太够 , 索性自己就把豆瓣电影的评论(短评)搞一搞吧 。
之前有写过哪吒那篇类似的 , 但今天这篇要写的像姨母般详细 。 本篇主要实现的是对任意一部电影短评(热门)的抓取以及可视化分析 。也就是你只要提供链接和一些基本信息 , 他就可以通用一套流程 。 文章插图
文章插图
分析
对于豆瓣爬虫 , what shold we 考虑?怎么分析呢?豆瓣电影首页
这个首先的话尝试就可以啦 , 打开任意一部电影 , 这里以姜子牙为例 。 打开姜子牙你就会发现它是非动态渲染的页面 , 也就是传统的渲染方式 , 直接请求这个url即可获取数据 。 但是翻着翻着页面你就会发现:未登录用户只能访问优先的界面 , 登录的用户才能有权限去访问后面的页面 。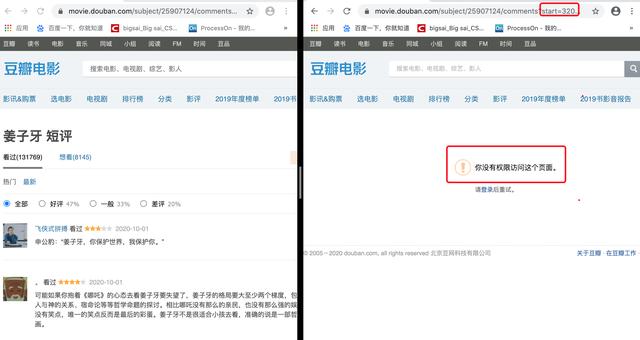 文章插图
文章插图
所以这个流程应该是 登录——> 爬虫——>存储——>可视化分析 。
这里提一下环境和所需要的安装装 , 环境为python3 , 代码在win和linux可成功跑 , 如果mac和linux不能跑友字体乱码问题还请私我 。 其中pip用到包如下,直接用清华 镜像下载不然很慢很慢(够贴心不) 。
pip install requests -i pip install matplotlib -i pip install numpy -i pip install xlrd -i pip install xlwt -i pip install bs4 -i pip install lxml -i pip install wordcloud -i pip install jieba -i 登录【python写一个豆瓣短评通用爬虫并可视化分析】豆瓣的登录地址
进去后有个密码登录栏 , 我们要分析在登录的途中发生了啥 , 打开F12控制台是不够的 , 我们还要使用Fidder抓包 。 文章插图
文章插图
打开F12控制台然后点击登录 , 多次试探之后发现登录接口也很简单: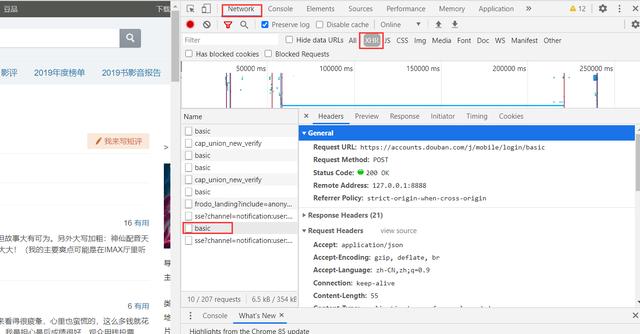 文章插图
文章插图
查看请求的参数发现就是普通请求 , 无加密 , 当然这里可以用fidder进行抓包 , 这里我简单测试了一下用错误密码进行测试 。 如果失败的小伙伴可以尝试手动登陆再退出这样再跑程序 。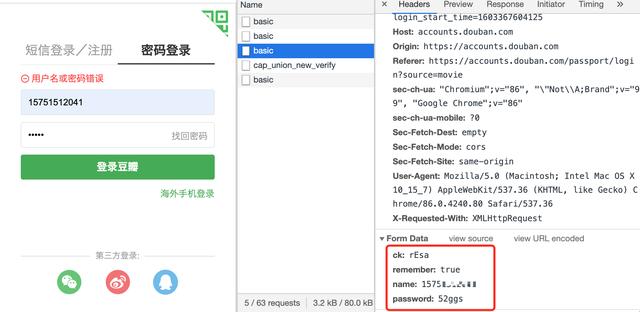 文章插图
文章插图
这样编写登录模块的代码:
url=''header={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36','Referer': '','Origin': '', 'content-Type':'application/x-www-form-urlencoded', 'x-requested-with':'XMLHttpRequest', 'accept':'application/json', 'accept-encoding':'gzip, deflate, br', 'accept-language':'zh-CN,zh;q=0.9', 'connection': 'keep-alive' ,'Host': 'accounts.douban.com' }data=http://kandian.youth.cn/index/{'ck':'','name':'','password':'','remember':'false','ticket':''}def login(username,password):globaldatadata['name']=usernamedata['password']=passworddata=http://kandian.youth.cn/index/urllib.parse.urlencode(data)print(data)req=requests.post(url,headers=header,data=data,verify=False)cookies = requests.utils.dict_from_cookiejar(req.cookies)print(cookies)return cookies这块高清之后 , 整个执行流程大概为: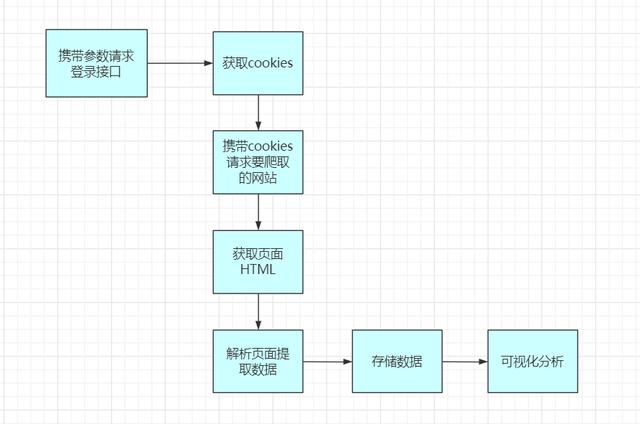 文章插图
文章插图
爬取成功登录之后 , 我们就可以携带登录的信息访问网站为所欲为的爬取信息了 。 虽然它是传统交互方式 , 但是每当你切换页面时候会发现有个ajax请求 。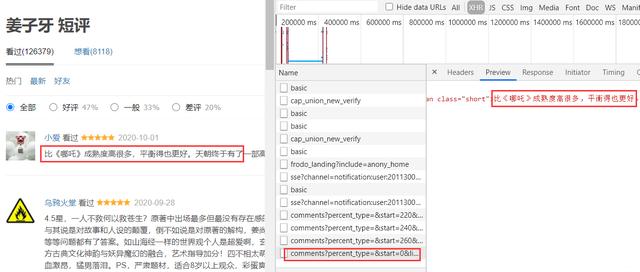 文章插图
文章插图
这部分接口我们可以直接拿到评论部分的数据 , 就不需要请求整个页面然后提取这部分的内容了 。 而这部分的url规律和之前分析的也是一样 , 只有一个start表示当前的条数在变化 , 所以直接拼凑url就行 。
也就是用逻辑拼凑url一直到不能正确操作为止 。
;start=0start=20start=40 --tt-darkmode-color: #A3A3A3;">对于每个url访问之后如何提取信息呢?我们根据css选择器进行筛选数据 , 因为每个评论他们的样式相同 , 在html中就很像一个列表中的元素一样 。
再观察我们刚刚那个ajax接口返回的数据刚好是下面红色区域块 , 所以我们直接根据class搜素分成若干小组进行曹祖就可以 。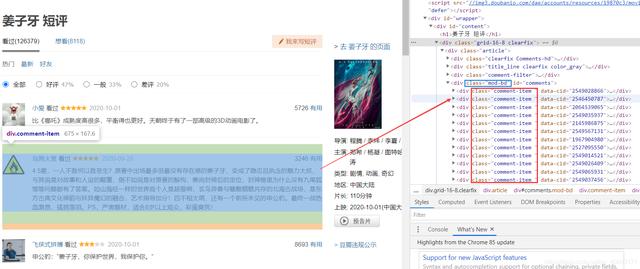 文章插图
文章插图
- 车企|华为不造车!但任正非加了一个有效期,3年
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 发展|新基建发展迅猛,必然会是一个巨大的市场机遇
- 易来|RA95显色只是起步,2020双12选灯必逛好店!
- 缺点|骁龙865+12GB已降至2399,X轴马达+55W快充,缺点只有一个
- 空间|垃圾文件正在吞噬你的C盘空间用这四种方法,还你一个干净的C盘
- 商业|AC有望建立一个商业帝国吗?
- 中国汽车|2020年,我们攒了一个局,串了一条链,下了一盘棋