cpu|只有阿里腾讯才懂的芯片秘密( 二 )
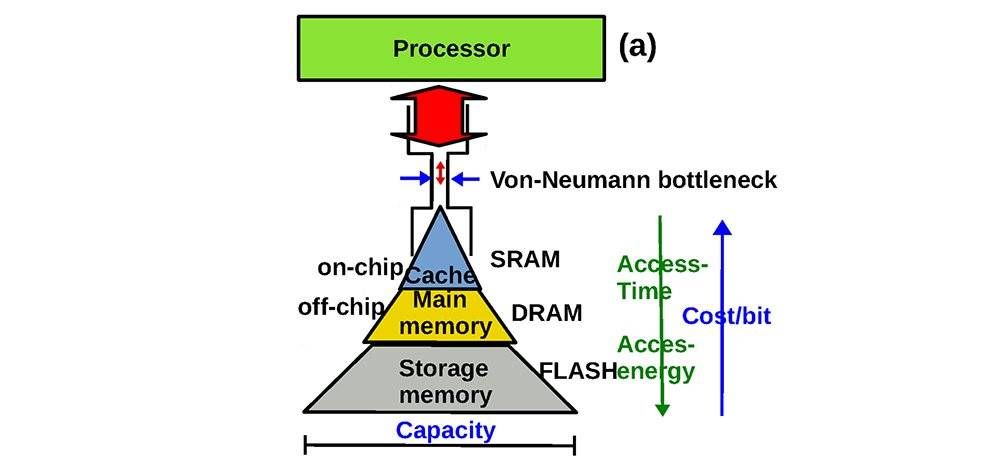
文章插图
很显然,对于服务器基础架构一直十分重视的云巨头,在以肉眼可见的方式,逐步“吞噬”服务器架构中的各个核心关键点——
以亚马逊AWS为例,在2015年收购以色列的安纳普尔纳峰实验室后,便从2017年开始,陆续推出了DPU芯片Nitro、Arm服务器CPU Graviton、Graviton2及Graviton3,以及机器学习训练加速器 Trainium 和机器学习推理加速器 Inferentia。
而阿里等中国云巨头在芯片研发上获得启发的时间,恰好是在AWS发布Nitro DPU前后。如今,基本也完成了从服务器CPU到AI加速器的“同等类别装备”。
基本可以明确的是,自亚马逊开了先河后,不断垂直整合云计算从底层到上层业务,把服务器架构自研能力掌握在自己手里,如今在顶级云厂商间已经达成了共识。
“阿里的野心,或者说魄力很大。”
一位不具名的服务器专家告诉虎嗅,阿里基础架构事业群AIS,在服务器架构自研与创新走的挺快,只是因为比较底层所以外界不太了解,知乎上甚至有人直接把他们归为“做运维的”。
由于这个事业群相当于整个阿里云软硬基础设施的“管家”,所以,各类技术专家集结在一起,必须在服务器、内核、容器、JVM、调度、数据库、存储、中间件等多个数据中心“节点”上做迭代与创新,当然,它也在采购和销售上有KPI指标。
“在存储这一块,他们是有一些想法的。基本是两条路, 第一个当然是买现成的三星海力士美光,另一个是从前年开始吧,阿里自己买‘颗粒’(内存芯片),来自己做DIMM。” 他说,AIS在实验室水平上应该没问题,量产可能会有挑战。
“更重要的是看他们的整合思路——加速卡(AI, 存储)、网路(DPU/SmartNIC)。芯片是平头哥或其他部门来做,但需求方则是AIS、阿里云以及蚂蚁金服。需求方也非常重要,决定了用什么、怎么用,以及怎么用能够让效能发挥到最大。”
他提醒我们要关注英特尔 IDM2.0开放战略,特别是不久前“要对外授权X86的策略和猜测”——“我想,很多人应该很快会有动作的”。
此外,根据虎嗅近一两年来从多方了解到的信息显示,阿里在云基础设施硬件创新和战略速度层面,虽然存在部分争议,但在国内的确要胜其他云厂商两三筹。
很明显,对国内存储市场的重视和投资,无论是保证供应链稳定还是技术创新,都极为有必要。
只有云厂商才能推动的存储芯片进步
在2020年写台积电时,我们就曾提过,如果说苹果、高通、英伟达们高端产品的成功,台积电的先进制程工艺必然是最大助力之一;那么台积电总是能占领最小制程高地的原因,前者也必然功不可没——
最好的下游技术与产品给你“导航”和试错,才能跟竞争对手打出一个漂亮的时间差。
那么云计算与半导体的关系同样如此。
譬如谷歌推出TPU时被普遍叫好,并使得GPU厂商产生警惕。很大原因便是,作为成千上万块芯片并行运算的使用者,云厂商太清楚芯片的问题到底出在哪儿了,毕竟样本实在是丰富。
早在几年前,多伦多大学曾做过一个关于“Dram致命缺陷”的重要课题。
他们经过多方周旋,终于从阿贡等大型国家实验室、谷歌和Facebook的大型数据中心取得了大量宝贵样本。让他们感到震惊的是,关于Dram的错误很常见,而一些数据中心的重大宕机事故更是源自Dram失常。
以谷歌为例,他们发现12% 到45% 的谷歌机器每年至少会遇到一次 DRAM 错误,有0.2%到4% 的机器由于 DRAM 错误无法纠正而意外关闭。
而在以往,无论是大型数据中心还是个人电脑中,产业内都会把Dram错误更多归咎于“软性问题”——根据IEEE杂志的解释,当物理设备在完全正常工作下,会受到某种短暂干扰(如宇宙射线产生的粒子)因而破坏了存储数据。
但这个想法此前几乎没有充分的实验支撑,某种程度上就是缺乏样本。没错,企业数据中心不愿透露,而实验室的样本量又少。实际上,经过他们的调查,结果令人震惊,其实大多数错误来自“硬性错误”。
没错,就是Dram芯片本身存在的问题。
调查者获得了谷歌某些数据中心的权限,在调查后发现,是一小部分机器造成了大部分错误。也就是说,错误倾向于一次又一次地出现在相同的内存模块上。
- CPU|惊喜大于失望,我眼中的RedmiK50电竞版
- 显卡|A卡只有走三A加成,以及专门搞A卡,优化的游戏表现才比N卡好
- 阿里|马云唯一出路是不断学习刘强东?
- |CPU也要内购氪金?这个确实有些颠覆认知了
- CPU|春季千元内处理器怎么选?别再考虑老产品,这次咱们买对不买错
- 淘宝|未发货秒退款规则大改,商家降本增效!阿里小二官方解读
- 阿里巴巴|土豆“龙王归位”控股优酷?阿里文娱“退出”了
- 拼多多|【黑马早报】小鹏汽车回应高管年薪超4亿;阿里将设立品牌自营旗舰店;小米12号创始员工离职;中国邮政咖啡店正式营业;星巴克单品涨价...
- CPU|英特尔12代酷睿移动处理器解析:未来将推出第三代“雅典娜”计划
- 京东|马云预言成笑话,京东有望取代华为成第一民企,阿里输在哪里?