
文章图片
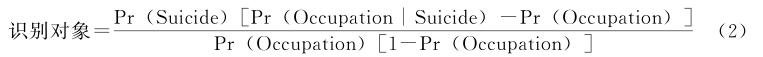
文章图片

文章图片

文章图片
庞珣:避免“下不该下的结论”——社会科学研究中的识别与信度
作者:庞珣 , 清华大学国际关系学系教授(北京100084) 来源:《中国社会科学评价》2021年第3期P62—P71;中国学派编辑:周悦
摘要:识别(identification)是在理论假定基础上将实证信息与研究对象进行独一无二的映射 , 是社会科学实证研究的基本任务和核心工作 。 社会科学正经历着两大变革 , 即数据革命(the Data Revolution)和识别革命(the Identification Revolution) 。 在数据革命似乎变一切“不可能”为“可能”时 , 识别革命却怀疑这些“可能性”的信度(credibility) , 诘问研究“变为可能”的代价 , 强调理论假定的清晰度(cleanness)和透明度(transparency) , 要求建立严格信度标准下的“设计驱动型”实证研究范式 。 在识别革命尚待推进的一些领域 , 大数据带来机遇的同时也伴随着研究缺乏信度、理论与实证脱节、过度量化等问题的凸显 。 强化识别意识和识别策略设计 , 提高实证研究的信度、连接理论和实证并恰当适度地使用数据及技术 , 对于大数据时代的社会科学发展具有迫切而深远的意义 。
关键词:识别革命 信度 设计驱动型研究 大数据 经验主义
责任编辑:张萍 褚国飞
当前社会科学研究正经历着数据革命和识别革命(又称“信度革命”)两大变革 。 它们都已持续多年并从根本上改变着研究的范式和形式 。 数据革命在近年来尤其高歌猛进 , 呈排山倒海之势 。 海量、多样和实时的数据在井喷式的新算法技术助力下 , 极大拓展了社会科学的研究议题和探索空间 。 相比而言 , 识别革命更像是“静悄悄的革命” , 但在其持续约四十年的时间里已经证明了它持久的生命力和创新性 。 识别革命要求对数据和技术采取前所未有的谨慎态度 , 强调以严格的研究设计来提高实证研究的信度 , 坚守科学内核而拒绝经验主义 。 在数据革命似乎把一切不可能变为可能时 , 识别革命却怀疑这些“可能”的信度 , 要求诘问研究“变为可能”的代价 。 识别革命在某种意义上是反机械化、反自动化和反技术流的 , 而数据革命则以将一切工作交予机器为评判进步的标准 。 如此 , 数据革命和识别革命形成了一个“双重运动” 。 数据革命以“技术”来强势扩展自己的边界 , 而识别革命则以捍卫研究的科学“价值”(信度)为使命 , 要将数据革命限制在某个合理的范围内以抵御经验主义的诱惑 。 已有实践表明 , 平衡数据革命与识别革命的“双重运动” , 对社会科学健康蓬勃发展至为关键 。 但在识别革命尚未确立地位的一些领域中 , 当数据革命的浪潮席卷而来时 , 令人担忧的问题和有识之士的焦虑也随之加深 。
例如 , 海量数据、前沿技术和强大计算能力貌似铜墙铁壁地保证着实证发现的信度 , 但令人眼花缭乱的“数据技术密集型”实证研究得出的结论却常常显得“不靠谱” 。 是什么的缺失造成了数据技术与研究信度之间的紧张关系?理论与实证脱节的情况依然严峻 , 大数据与计算社会科学等新兴研究范式的发展不仅没有起到弥合作用 , 反而在加速两者之间的脱节 。 理论与实证脱节的症结究竟在哪里?是否不可避免?数据革命带来了对社会科学“过度量化”的批评和担忧 。 数据及其分析技术在什么意义上被“过度”使用了?“过度”中的“度”在哪里?过度使用在什么意义上损害到社会科学?
以上问题的出现可以视为数据革命趋向“脱嵌”于研究的科学内核的表现 。 识别革命通过拒绝经验主义而对这种趋势进行回推 , 对于保证数据革命的“嵌入”——服务于追求持久性知识而非满足于对经验现象的追逐——十分必要 。 缺乏识别革命回推绝非数据革命的完胜 , 如果深切的焦虑得不到回应、严重的问题得不到解决 , 社会科学中的一些领域也可能放弃数据革命带来的机遇作为保护社会科学精神内核的代价 。
- 英伟达|「资讯」NV最强AI黑科技?能将文字描述一键转为逼真画像
- 蜘蛛|世界上长相恐怖但危害不高的5种动物
- |「弹指」的速度到底有多快?物理学研究揭秘:只要0.007秒!
- 36氪|36氪首发 | 「心愿盒Match Box」获百万级美元种子轮融资,用派样实现消费者体验共创
- 网易云音乐|「失物追踪」专家 Tile 被收购,曾批评苹果不公平竞争
- 蜘蛛|牡丹花下死的袋鼩,一次啪啪啪长达14个小时献出生命,它有瘾吗?
- 软件|「有手就行」无需 Root 卸载预装软件,精简过的老年机又行了
- 英伟达|「技巧」NVIDIA的“FSR”也来了!它到底如何呢?
- 移民|如果人类消失了,留下的“垃圾”何去何从?一组漫画「科普」揭秘
- 企业微信|36氪首发 | 企业微信服务商「探马SCRM」获B+轮3000万美元融资,钟鼎资本领投