目标|中科院软件所发布最大零售场景检测计数数据集
高子越 科技日报采访人员 张佳星
超市里的一摞碗用人工智能怎样计数?AI目前是难以准确计数的 。 这类问题不解决 , 无人商超将只能是个“传说” 。
日前 , 中国科学院软件研究所智能软件研究中心发布了目前学术界最大的零售场景检测计数任务数据集——Locount , 该数据集包含的商品实例标注数量达到200万个 。
【目标|中科院软件所发布最大零售场景检测计数数据集】相关科研人员表示 , 新的数据集针对被检测物体高度重叠场景中 , 无法通过传统检测框区分和计数的问题 , 给出了完整的基础解决方案和新的评估标准 , 有利于解决复杂场景下的目标检测和计数问题 , 同时也适用于现实场景中长尾分布、少样本学习等多个潜在研究方向 。 该工作被国际人工智能大会AAAI 2021收录 。 文章插图
文章插图
据介绍 , 该数据集经过团队近2年的广泛收集及测试研究 , 共包含约200多万个商品实例标注信息 , 涵盖了140种商品类别 。 其中每个标注框包含了同类商品实例及其数量 , 与目前已有商品类型数据集相比 , 具有明显优势 。 它不仅填补了真实生活场景中检测和计数联合任务问题的空白 , 并定义了新的检测计数任务及新的评价指标 , 为解决目标检测领域严重遮挡问题提供了重要基础 , 还将在日常生活场景中赋能智能货架管理 , 为无人自助结算等智能化消费方式带来变革 。
研究发现 , 现在的目标检测任务通常使用一个矩形框来预测单个目标的位置 , 因为传统目标检测数据集的遮挡比例较少 , 尤其缺少多个目标之间严重遮挡的情况(例如多个目标重叠比例超过90%) 。 但在零售场中却普遍存在这种情况 , 商超货架内的商品通常在上下和前后两个方向上有所重叠 。 如图1(c)所示 , 传统的表示方法无法适用于商品零售场景 , 因为同一类别商品重叠摆放会存在严重遮挡的现象 , 在实际使用中也无须精确定位每一个实例目标 。 文章插图
文章插图
因此 , 该团队提出了一种同时进行对象定位和计数的新任务 。 具体来说 , 如图1(d)所示 , 如果多个目标是相互严重遮挡且属于同一个类别 , 新的任务为预测出该目标簇中所有目标框合并的最小包围框及对应的实例数量 。
此外 , 为了评估不同算法在该任务上的性能 , 团队还设计了一种新的评价标准 , 以反映算法出现目标丢失、对同一实例的重复检测、错误检测、错误计数等情况 。
当前传统方法和常见的深度学习网络还无法很好地解决Locount提出的新挑战 。 为了能更好地研究复杂和密集场景下 , 尤其是目标高度重叠时的检测和计数问题 , 团队希望更多科研人员能够借助Locount数据集 , 探索出更准确、高效的任务解决思路和方法 。 同时 , 这一数据集也可以为现实场景中长尾分布、少样本学习等多个潜在的研究方向提供基础支持 。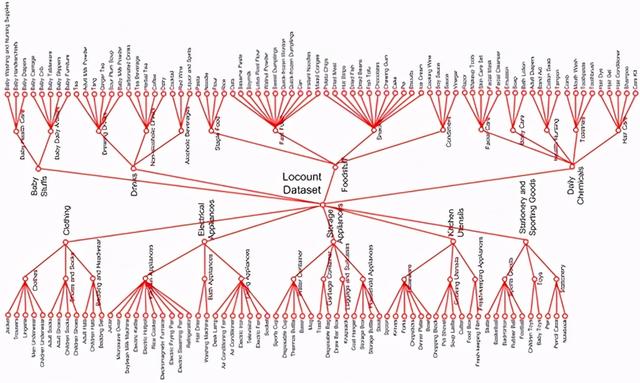 文章插图
文章插图
论文下载地址:
(文中图片由作者提供)
编辑:刘义阳
- 芯片|功率半导体有多紧俏?博世亲自下场生产碳化硅芯片,目标产能上亿颗!
- 支付宝|突破2项关键技术,中科院又立功了,事关量子计算和3D打印
- 目标|目标用户从哪来?
- 滴滴出行|中科院才是联想电脑的创始人,股改之前,联想电脑是中科院的全资子公司
- 柳传志|司马南撕柳传志,消费者呼唤中科院发声
- 华为|中科院再立新功,突破2项关键技术,展现中国实力
- 高德地图|三星S21 FE:价格遭曝光!三星S22:已定下目标!
- 领导者|融资丨「奕斯伟计算」完成25亿元C轮融资,目标物联网芯片领域全球领导者
- 电信|美团加持、ipo在即,东呈“万店”目标正在“暗暗”酝酿
- 联想|疑似中科院正式回应联想事件,郎咸平站队联想,司马南腹背受敌?