理解真实世界中 Go 的并发 BUG
有几个学生研究归纳了go编程中的并发bugs , 发表了一篇(英文)论文:《Understanding Real-World Concurrency Bugs in Go》 。 为你下载好了 PDF , 关注公众号 Go语言中文网 , 回复 gostudy 获取 。
在此做一个笔记 , 便于查阅 。
文章以六个产品级go应用作为研究对象:Docker、Kubernetes、etcd、gRPC、CockroachDB、BoltDB , 总共研究了这些应用中的171个bug , 研究它们的根本原因 , 并重现这些bugs , 以及检查它们的修复补丁 。 最后用两个现有go并发bug检测器测试了这些bug 。
文章试图回答一个问题:对于两种线程/协程间通信机制 , 消息传递机制和共享内存机制 , 哪个更不容易出错?
文章从两个维度对bug进行了分类 , bug原因(对共享内存的误用、对消息传递的误用)和bug表现(阻塞性bug、非阻塞性bug) 。
研究结果及提交日志可以在以下地址查阅:
many concurrency bugs are caused by the mixed usage of message passing and other new semantics and new libraries in Go, which can easily be overlooked but hard to detect.
背景使用共享内存实现同步Go支持协程间共享内存 , 提供了多种传统的同步手段 , 如锁(Mutex)、读写锁(RWMutex)、条件变量(Cond)、原子读写(atomic) 。 go的RWMutex实现与C中的pthread_rwlock_t不同 , go中的写锁请求优先级高于读锁 。
go中还有一些新特性 , Once保证一个函数只执行一次:使用 Once.Do(f) 方法 , 即使这一语句被多个协程调用了多次 , 也只有第一次的时候 , 函数f会被执行 。
和C中的pthread_join类似 , go使用WaitGroup来实现等待协程对其他协程的等待 。
使用消息传递实现同步channel(chan)是go的新特性 , 学习go语言编程的都应该熟悉了 。 channel分有缓冲和无缓冲两种(buffered and unbuffered) 。
使用select可以从多路channel中进行选择 。 当有多路case有效时 , select会从中随机选择一个去执行 , 这种随机性可能会造成bug 。
Go引入了几种新机制来简化协程间的交互 , 如用context携带数据传递在不同协程之间 , 还有Pipe可在读协程和写协程之间传递流式数据 。 这两种都是新的消息传递机制 , 不注意的话可能引起新的并发bug 。
Go并发模型在研究并发bug前 , 文章先研究了go中的并发模型 。
首先统计了那几个应用中创建gorutine的(静态)语句数量(位置数量) , 如下表: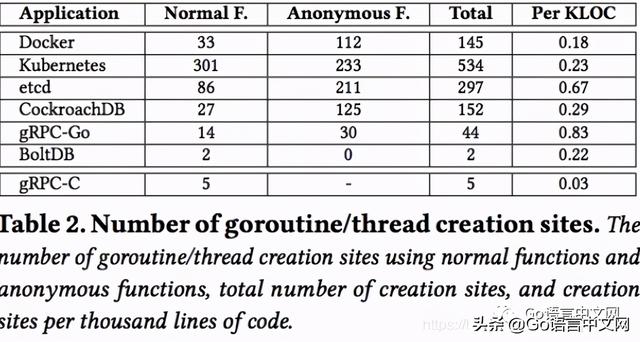 文章插图
文章插图
img
文章觉得喜欢用匿名函数创建gorutine的多些(除了kubernetes和BoltDB) , 另外还发现C语言版gRPC比go语言版更少创建线程语句 。
然后 , 文章还统计了各种同步机制的使用比例 , 如下图: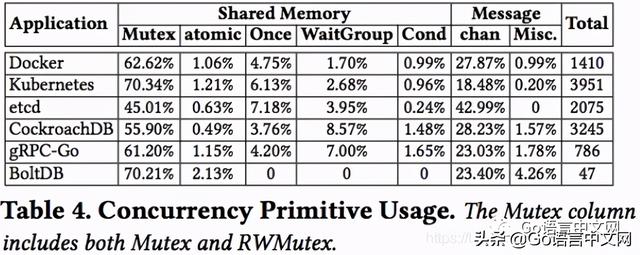 文章插图
文章插图
img
从中可以看出 , 共享内存机制的锁还是用得最多啊!
同时 , 这些机制的使用比例 , 随着项目时间推进 , 是否有什么变化趋势的?似乎没有明显变化 , 如下截图: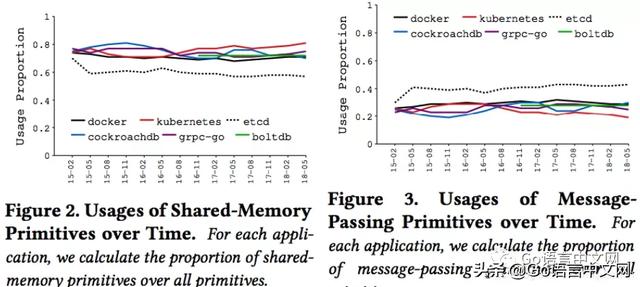 文章插图
文章插图
img
Bug分类分类如下: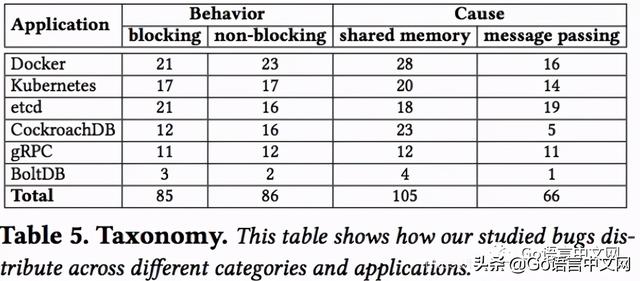 文章插图
文章插图
img
从数值看 , 阻塞性bug和非阻塞性bug出现数量差不多 。
(笔者注:对于原因而言 , 从数值上看使用共享内存的造成bug比较多 , 但是这里只统计了绝对值 , 没有和前面共享机制的使用量结合起来考虑比例 , 似乎不大妥当 。 )
对于这些bug , 文章作者使用相应有bug的版本 , 根据bug报告中的操作尝试重现这些bug , 结果发现并发bug是很难重现的 。 从而这些bug存在时间都比较长 , 而一旦被发现 , 一般会比较快地得到解决 。 bug生存时间统计如下: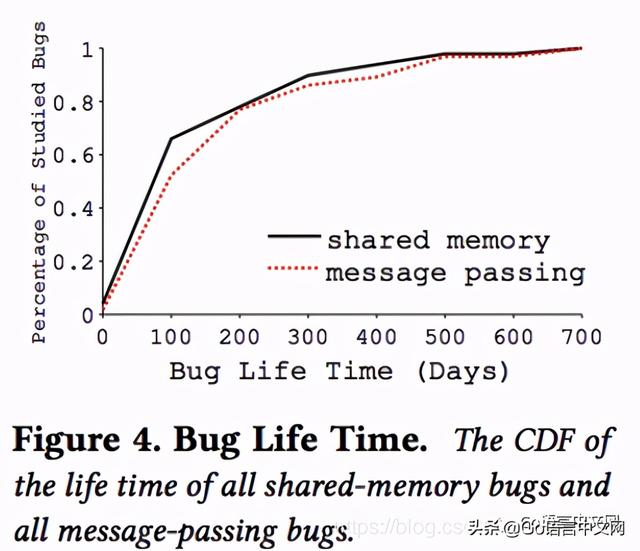 文章插图
文章插图
img
Bug原因分析1、阻塞性bug统计如下: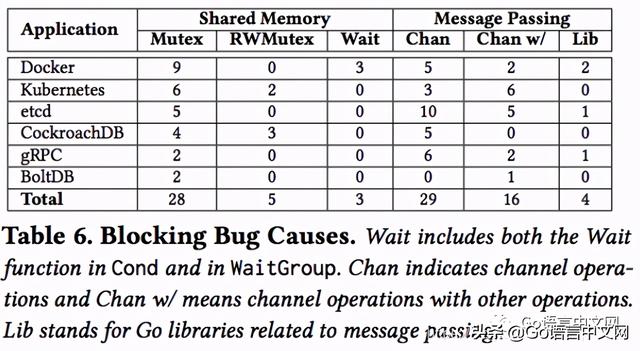 文章插图
文章插图
img
具体分析
(1)对共享内存保护的失误:
Mutex:28个阻塞性bug由对锁的不当使用造成 , 包括重复锁、以冲突的顺序申请锁、忘记解锁* 。 这些bug都是传统bug , 文章觉得传统的死锁检测算法应该能检测出这类bug 。
RWMutex:前面提到过 , go中的写锁优先级高 。 这种实现机制可以造成如下bug:协程A对同一个RWMutex申请两次读锁 , 但在这两次申请中间 , 协程B申请写锁 。 此时 , 由于A已经持有了一个读锁 , 而写锁又是排他性的 , 所以B被阻塞 。 然后 , A第二次申请读锁时 , 由于B的写锁优先级高 , 所以A的读锁必须排在B的写锁请求之后 , 导致A被阻塞 。 从而发生了死锁 。
- 技术|张勇内部分享,解读阿里巴巴技术路线:把先进技术用到真实的大场景里去
- 苹果|要是不看真实数据,我还以为国产机将iPhone打成下一个三星了呢
- 搜狐|施耐德电气在欧洲电力展推出面向未来电网的全生命周期管理解决方案
- 半导体|台积电董事长刘德音:未来10年将会感受到真实与虚拟世界结合
- 红米手机|印度冷知识:印度人给这个世界带来的6项伟大发明
- 联想|联想认为电脑销量世界第一很光荣?美国禁用windows或芯片,一夜之间就关门
- vivo|真实案例表明:拍照效果正左右用户意向,vivo手机简化了自拍步骤
- 小米科技|世界艾滋病日苹果提供六个新的Apple Watch表盘\\iOS 15.1停止验证
- 联想|联想电竞旗舰手机,降价1600元也无人问津?内行人告诉你真实原因
- deepin|郎咸平谈当年联想的两次收购,一种做大做强,成为世界500强的病态心理