机器翻译:谷歌翻译是如何对几乎所有语言进行翻译的?
全文共13204字 , 预计学习时长34分钟 文章插图
文章插图
谷歌翻译大家想必都不陌生 , 但你有没有想过 , 它究竟是如何将几乎所有的已知语言翻译成我们所选择的语言?本文将解开这个谜团 , 并且向各位展示如何用长短期记忆网络(LSTM)构建语言翻译程序 。
本文分为两部分 。 第一部分简单介绍神经网络机器翻译(NMT)和编码器-解码器(Encoder-Decoder)结构 。 第二部分提供了使用Python创建语言翻译程序的详细步骤 。 文章插图
文章插图
图源:谷歌
什么是机器翻译?
机器翻译是计算语言学的一个分支 , 主要研究如何将一种语言的源文本自动转换为另一种语言的文本 。 在机器翻译领域 , 输入已经由某种语言的一系列符号组成 , 而计算机必须将其转换为另一种语言的一系列符号 。
神经网络机器翻译是针对机器翻译领域所提出的主张 。 它使用人工神经网络来预测某个单词序列的概率 , 通常在单个集成模型中对整个句子进行建模 。
凭借神经网络的强大功能 , 神经网络机器翻译已经成为翻译领域最强大的算法 。 这种最先进的算法是深度学习的一项应用 , 其中大量已翻译句子的数据集用于训练能够在任意语言对之间的翻译模型 。 文章插图
文章插图
谷歌语言翻译程序
理解Seq2Seq架构
顾名思义 , Seq2Seq将单词序列(一个或多个句子)作为输入 , 并生成单词的输出序列 。 这是通过递归神经网络(RNN)实现的 。 具体来说 , 就是让两个将与某个特殊令牌一起运行的递归神经网络尝试根据前一个序列来预测后一个状态序列 。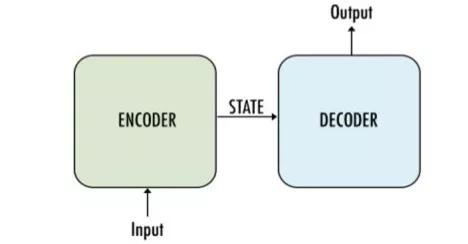 文章插图
文章插图
一种简单的编码器-解码器架构
它主要由编码器和解码器两部分构成 , 因此有时候被称为编码器-解码器网络 。
· 编码器:使用多个深度神经网络层 , 将输入单词转换为相应的隐藏向量 。 每个向量代表当前单词及其语境 。
· 解码器:与编码器类似 。 它将编码器生成的隐藏向量、自身的隐藏状态和当前单词作为输入 , 从而生成下一个隐藏向量 , 最终预测下一个单词 。
任何神经网络机器翻译的最终目标都是接收以某种语言输入的句子 , 然后将该句子翻译为另一种语言作为输出结果 。 下图是一个汉译英翻译算法的简单展示: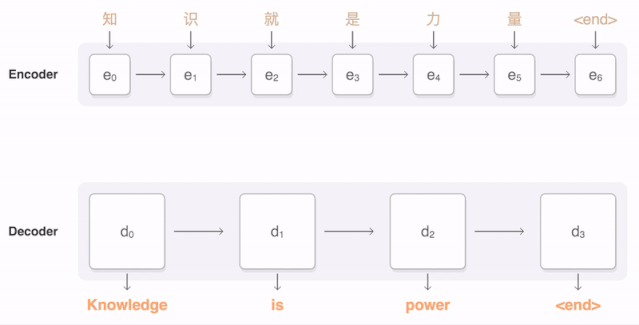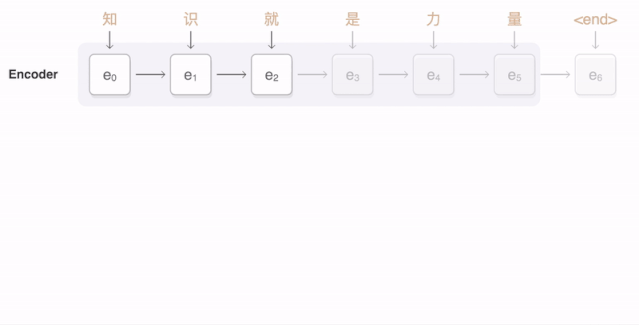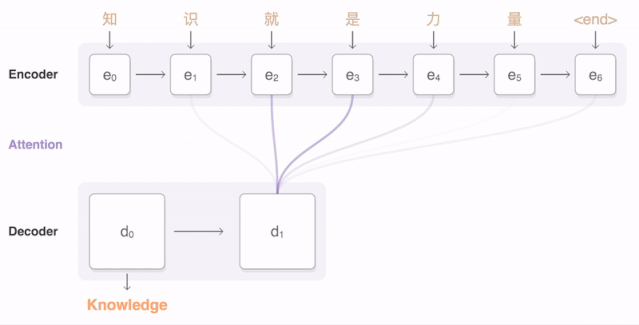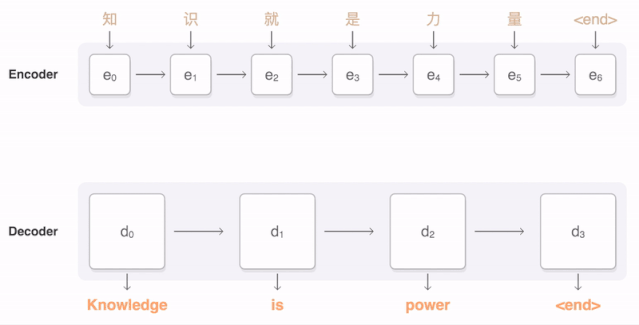 文章插图
文章插图
将“Knowledge ispower”翻译成汉语 。
它如何运行?
第一步 , 通过某种方式将文本数据转换为数字形式 。 为了在机器翻译中实现这一点 , 需要将每个单词转换为可输入到模型中的独热编码(One Hot Encoding)向量 。 独热编码向量是在每个索引处都为0(仅在与该特定单词相对应的单个索引处为1)的向量 。 文章插图
文章插图
独热编码
为输入语言中的每个唯一单词设置索引来创建这些向量 , 输出语言也是如此 。 为每个唯一单词分配唯一索引时 , 也就创建了针对每种语言的所谓的“词汇表” 。 理想情况下 , 每种语言的词汇表将仅包含该语言的每个唯一单词 。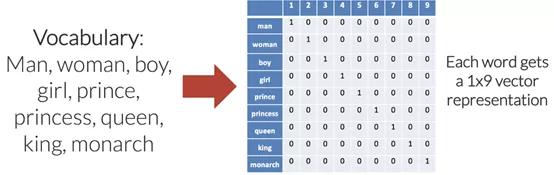 文章插图
文章插图
如上图所示 , 每个单词都变成了一个长度为9(这是词汇表的大小)的向量 , 索引中除去一个1以外 , 其余全部都是0 。
通过为输入和输出语言创建词汇表 , 人们可以将该技术应用于任何语言中的任何句子 , 从而将语料库中所有已翻译的句子彻底转换为适用于机器翻译任务的格式 。
现在来一起感受一下编码器-解码器算法背后的魔力 。 在最基本的层次上 , 模型的编码器部分选择输入语言中的某个句子 , 并从该句中创建一个语义向量(thought vector) 。 该语义向量存储句子的含义 , 然后将其传递给解码器 , 解码器将句子译为输出语言 。 文章插图
文章插图
编码器-解码器结构将英文句子“Iam astudent”译为德语
就编码器来说 , 输入句子的每个单词会以多个连续的时间步分别输入模型 。 在每个时间步(t)中 , 模型都会使用该时间步输入到模型单词中的信息来更新隐藏向量(h) 。
- 监管机构|谷歌和Meta被俄罗斯监管机构告上法庭,或面临巨额罚款
- 华为mate|谷歌Pixel Watch最新消息,有望明年初发布
- 谷歌|奥密克戎来袭,谷歌称复工计划无限推迟
- 谷歌|科技巨头创始人正退出舞台!谷歌阿里字节等10大创始人退出史
- 华为鸿蒙系统|牛!龙芯二进制翻译功能,可运行安卓、windows、linux软件
- 验证码|如何把谷歌两步验证设计到产品中
- 英特尔|微软、谷歌、IBM之后,印度人又掌管一家美国科技公司,年仅37岁
- 苹果|曾被美国拒签8次,山东程序员打败谷歌苹果,靠螺丝刀身家涨200亿
- 操作系统|谷歌浏览器操作系统
- 对端|小米公开同声传译通话专利,可对用户的原声进行翻译