告别CNN?一张图等于16x16个字,计算机视觉也用上Transformer了
 文章插图
文章插图 文章插图
文章插图
编译 | 凯隐
出品 | AI科技大本营(ID:rgznai100)
Transformer是由谷歌于2017年提出的具有里程碑意义的模型 , 同时也是语言AI革命的关键技术 。 在此之前的SOTA模型都是以循环神经网络为基础(RNN, LSTM等) 。 从本质上来讲 , RNN是以串行的方式来处理数据 , 对应到NLP任务上 , 即按照句中词语的先后顺序 , 每一个时间步处理一个词语 。
相较于这种串行模式 , Transformer的巨大创新便在于并行化的语言处理:文本中的所有词语都可以在同一时间进行分析 , 而不是按照序列先后顺序 。 为了支持这种并行化的处理方式 , Transformer依赖于注意力机制 。 注意力机制可以让模型考虑任意两个词语之间的相互关系 , 且不受它们在文本序列中位置的影响 。 通过分析词语之间的两两相互关系 , 来决定应该对哪些词或短语赋予更多的注意力 。
相较于RNN必须按时间顺序进行计算 , Transformer并行处理机制的显著好处便在于更高的计算效率 , 可以通过并行计算来大大加快训练速度 , 从而能在更大的数据集上进行训练 。 例如GPT-3(Transformer的第三代)的训练数据集大约包含5000亿个词语 , 并且模型参数量达到1750亿 , 远远超越了现有的任何基于RNN的模型 。
现有的各种基于Transformer的模型基本只是与NLP任务有关 , 这得益于GPT-3等衍生模型的成功 。 然而 , 最近ICLR 2021的一篇投稿文章开创性地将Transformer模型跨领域地引用到了计算机视觉任务中 , 并取得了不错地成果 。 这也被许多AI学者认为是开创了CV领域的新时代 , 甚至可能完全取代传统的卷积操作 。
论文链接:
其中 , Google的Deepmind 研究科学家Oriol Vinyals的看法很直接:告别卷积 。
以下为该论文的详细工作: 文章插图
文章插图
基本内容
Transformer的核心原理是注意力机制 , 注意力机制在具体实现时主要以矩阵乘法计算为基础 , 这意味着可以通过并行化来加快计算速度 , 相较于只能按时间顺序进行串行计算的RNN模型而言 , 大大提高了训练速度 , 从而能够在更大的数据集上进行训练 。
此外 , Transformer模型还具有良好的可扩展性和伸缩性 , 在面对具体的任务时 , 常用的做法是先在大型数据集上进行训练 , 然后在指定任务数据集上进行微调 。 并且随着模型大小和数据集的增长 , 模型本身的性能也会跟着提升 , 目前为止还没有一个明显的性能天花板 。
Transformer的这两个特性不仅让其在NLP领域大获成功 , 也提供了将其迁移到其他任务上的潜力 。 此前已经有文章尝试将注意力机制应用到图像识别任务上 , 但他们要么是没有脱离CNN的框架 , 要么是对注意力机制进行了修改 , 导致计算效率低 , 不能很好地实现并行计算加速 。 因此在大规模图片分类任务中 , 以ResNet为基本结构的模型依然是主流 。
这篇文章首先尝试在几乎不做改动的情况下将Transformer模型应用到图像分类任务中 , 在 ImageNet 得到的结果相较于 ResNet 较差 , 这是因为Transformer模型缺乏归纳偏置能力 , 例如并不具备CNN那样的平移不变性和局部性 , 因此在数据不足时不能很好的泛化到该任务上 。
然而 , 当训练数据量得到提升时 , 归纳偏置的问题便能得到缓解 , 即如果在足够大的数据集上进行与训练 , 便能很好地迁移到小规模数据集上 。
在此基础上 , 作者提出了Vision Transformer模型 。 下面将介绍模型原理 。 文章插图
文章插图
模型原理
该研究提出了一种称为Vision Transformer(ViT)的模型 , 在设计上是尽可能遵循原版Transformer结构 , 这也是为了尽可能保持原版的性能 。
虽然可以并行处理 , 但Transformer依然是以一维序列作为输入 , 然而图片数据都是二维的 , 因此首先要解决的问题是如何将图片以合适的方式输入到模型中 。 本文采用的是切块 + embedding的方法 , 如下图: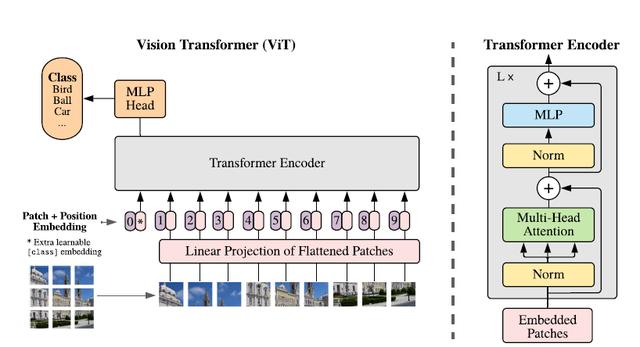 文章插图
文章插图
首先将原始图片划分为多个子图(patch) , 每个子图相当于一个word , 这个过程也可以表示为: 文章插图
文章插图
其中x是输入图片 , xp则是处理后的子图序列 , P2则是子图的分辨率 , N则是切分后的子图数量(即序列长度) , 显然有
- 风波|杀貂风波致商户疯抢进口貂皮:一张皮涨200元,一件大衣成本增千元
- 主题|GNN、RL崛起,CNN初现疲态?ICLR 2021最全论文主题分析
- 海淀区|海淀城市大脑“时空一张图”上线
- 塑料颗粒|别不信!你每天吃的塑料量,一周后可能等于一张信用卡!
- 纸条|女子网购买了一双鞋,收货后发现一张纸条,看完她怒了
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- 互联网巨头们打出一张张牌,都直击卖菜小贩,线下实体该何去何从
- 告别卡顿,一份手机清理指南
- 图解3种常见的深度学习网络结构:FC、CNN、RNN
- 服务|听说我上热搜了?