天猫国际通过 Hologres 进行排行榜的实时交互式分析
一.业务背景天猫国际营销活动分析实时排行榜是在大促中帮助业务快速的分析商家或者品牌的交易和流量的数据情况 , 给下一步大促的销售目标 , 流量蓄水等等做出运营决策;尤其是在活动当天当发现行业的问题之后 , 仅仅靠子行业的拆分不足以确定具体的问题 , 也不一定有具体的业务抓手 , 所以需要有到商家、品牌和商品粒度的数据来快速定位问题 。 文章插图
文章插图
二.原技术方案原始技术方案的架构如下图所示 , 可以看到是非常典型的Lambda架构 , 实时和离线分别是两套系统 , 离线数据通过MaxCompute(原MaxCompute)轻度汇总同步至MySQL , 实时增量数据通过Blink清洗后同步至HBase , 最后在数据服务里面以View的形式将实时和离线数据合并 , 提供对外服务 。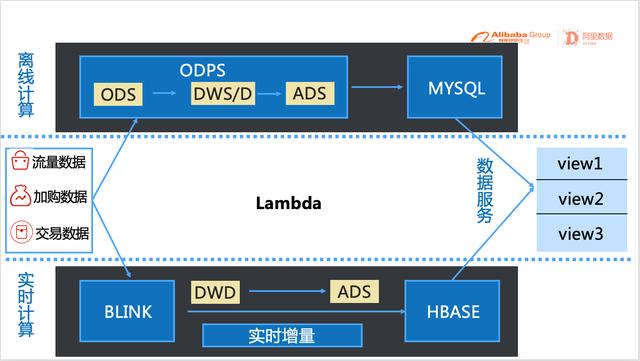 文章插图
文章插图
整个架构在实际业务执行中会有非常多的痛点 , 典型的有以下几个:
1)ADS层模型任务多
流计算和批处理任务都分别需要开发基于商品 , 卖家 , 品牌粒度的满足应用层的三个ADS模型数据 , 三个数据同步任务 , 分别需要创建三个oneservice服务 , 满足三个数据模块应用 。
2)计算过程数据膨胀
在营销活动分析的场景下 , 看数据都是基于天猫国际业务类型和行业为大前提 , 因此通常在离线和实时的计算任务中 , 我们都是并行同时计算好不同的bu类型和所有的行业粒度的数据 , 这就导致了计算的过程中的数据的大量膨胀 。
3)流批分离
当前产品上根据时间进行选择读取实时数据还是离线数据 , 三天之内的数据通过实时任务计算的数据 , 三天前的历史数据是通过批处理任务计算的离线数据 , 存在两套任务同时运行 , 增加了运维的复杂性 。
4)产品搭建逻辑复杂
每一个产品展示的报表模块都需要通过实时数据提供的os接口和离线数据提供的os来进行 , 产品搭建的工作量比较大 , 通过时间来判断什么时候来读取离线os的数据 , 什么时候来读取实时os的数据 , 逻辑比较繁杂 。
三.架构升级思考策略思考:为了提升研发效率和产品搭建的效率 , 我们只需要开发到DWD层的明细数据 , 明细数据只需要存储叶子类目 , 在交互式分层层面按需去关联行业维表 , 来提供对外随机的查询服务 , 从而节省了构建ADS层的多个模型数据以及数据服务接口的时间 , 在产品搭建上基于一个数据接口就能满足多个不同的应用场景的数据服务 , 提升产品搭建层面的效率 , 降低了产品搭建时的逻辑代码的复杂性 。
策略:我们希望能够有一款产品 , 能统一计算写入任务 , 做到流批统一 , 对外提供自由的交互式查询服务 。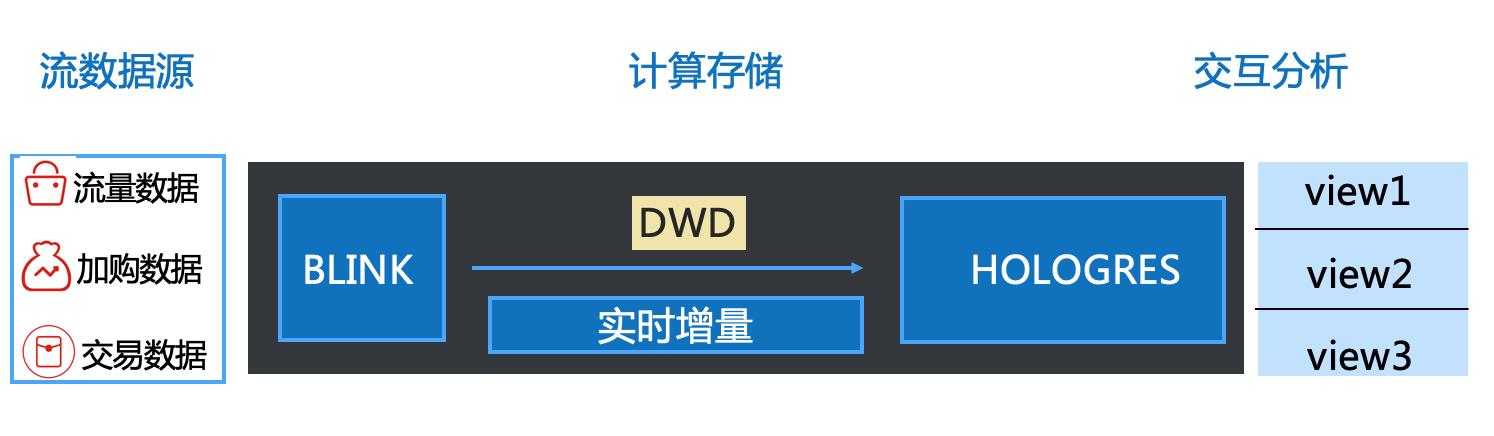 文章插图
文章插图
四.产品技术选型在产品技术选型之前 , 需要先梳理业务需要用到的表以及数据量 , 选取几张最具代表性的表用于验证实际业务场景中产品技术可行性 , 以及验证关键指标性能问 , 包括查询QPS、写入TPS等 。 主要选取的表以及数据量如下:
(1)交易明细数据表
| buyer_id + item_id +order_id ||20191111|4800W||20200618|600W||20200721|300W|(2)流量IPV明细数据表
| visitor_id + item_id||20191111|2.1亿||20200618|7000W||20200721|2600W|在技术选型方面 , 我们锁定了两款产品 , 一款是AnalyticDB for MySQL , 一款是Hologres 。 ADB是阿里云数据库事业部团队提供的云原生数据仓库AnalyticDB MySQL版 , 是阿里巴巴自主研发的海量数据实时高并发在线分析云计算服务 。 Hologres是阿里云计算平台事业部提供的一款全面兼容PostgreSQL协议并与大数据生态无缝打通的实时交互式分析产品 。 从实际业务场景出发 , 两者的主要区别有以下几点:
1)与MaxCompute的打通性
Hologres:与MaxCompute打通 , 可以直接通过外部表读取MaxCompute数据进行查询分析 , 无需存储就能查询 。
ADB:能加速查询MaxCompute , 提供复杂交互式分析、实时混合数据仓库等多种场景 。
2)成本方面
从我们每年ADB和Hologres的的单价上对比 , Hologres成本相比ADB略微低 。
3)灵活度
均能满足OLAP场景 , Hologres兼容兼容PostgreSQL生态 , ADB坚兼容MySQL协议 , 均能满足实时和离线批量的数据导入和分析 。
4)性能
以下是Hologers的测试性能 , 数据量和大小均以MaxCompute的存储格式为准 , 没有进行一些特殊的索引和优化处理 。
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 中国|中国软件国际与深圳市政府达成战略合作协议 助力打造“创新之都“
- 操作|[LIVE On]黄敏贤和郑多彬充满心碎的下午:机器操作每次都不能通过测试
- 发免|发错货道歉就完了? 天猫超市推出“错发免退”服务
- 商务参赞柏|秘鲁海外馆正式入驻京东国际 秘鲁期待与中国更多线上经贸合作
- 五金|我院承担的顺德区家居五金国际质量比对项目顺利通过成果验收
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 附属|陈唱国际附属向APM附属公司采购若干零件
- Reno5|通过HDR10+认证!OPPO Reno5惊喜果然不止这几点
- 方式|富维薄膜计划通过公开招标方式出售Dornier生产线