hive学习笔记之十:用户自定义聚合函数(UDAF)
本篇概览
- 本文是《hive学习笔记》的第十篇 , 前文《hive学习笔记之九:基础UDF 》实践了UDF的开发、部署、使用 , 那个UDF适用于一进一出的场景 , 例如将每条记录的指定字段转为大写;
- 除了一进一出 , 在使用group by的SQL中 , 多进一出也是常见场景 , 例如hive自带的avg、sum都是多进一出 , 这个场景的自定义函数叫做用户自定义聚合函数(User Defiend Aggregate Function , UDAF) , UDAF的开发比一进一出要复杂一些 , 本篇文章就一起来实战UDAF开发;
- 本文开发的UDAF名为udf_fieldlength, 用于group by的时候 , 统计指定字段在每个分组中的总长度;
- 在一些旧版的教程和文档中 , 都会提到UDAF开发的关键是继承UDAF.java;
- 打开hive-exec的1.2.2版本源码 , 却发现UDAF类已被注解为Deprecated;
- UDAF类被废弃后 , 推荐的替代品有两种:实现GenericUDAFResolver2接口 , 或者继承AbstractGenericUDAFResolver类;
- 现在新问题来了:上述两种替代品 , 咱们在做UDAF的时候该用哪一种呢?
- 打开AbstractGenericUDAFResolver类的源码瞅一眼 , 如下所示 , 是否有种恍然大悟的感觉 , 这个类自身就是GenericUDAFResolver2接口的实现类:
public abstract class AbstractGenericUDAFResolverimplements GenericUDAFResolver2{@SuppressWarnings("deprecation")@Overridepublic GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info)throws SemanticException {if (info.isAllColumns()) {throw new SemanticException("The specified syntax for UDAF invocation is invalid.");}return getEvaluator(info.getParameters());}@Overridepublic GenericUDAFEvaluator getEvaluator(TypeInfo[] info)throws SemanticException {throw new SemanticException("This UDAF does not support the deprecated getEvaluator() method.");}}- 既然源码都看了 , 也就没啥好纠结的了 , 继承父类还是实现接口都可以 , 您自己看着选吧 , 我这里选的是继承AbstractGenericUDAFResolver类;
- 在编码前 , 要先了解UDAF的四个阶段 , 定义在GenericUDAFEvaluator的Mode枚举中:
- COMPLETE:如果mapreduce只有map而没有reduce , 就会进入这个阶段;
- PARTIAL1:正常mapreduce的map阶段;
- PARTIAL2:正常mapreduce的combiner阶段;
- FINAL:正常mapreduce的reduce阶段;
- 开发UDAF时 , 要继承抽象类GenericUDAFEvaluator , 里面有多个抽象方法 , 在不同的阶段 , 会调用到这些方法中的一个或多个;
- 下图对每个阶段调用了哪些方法说得很清楚:
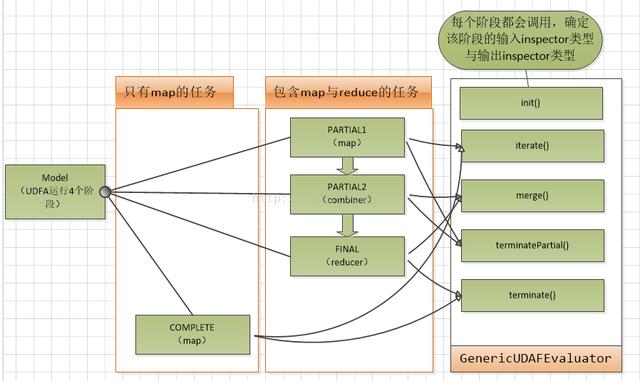 文章插图
文章插图- 下图对顺序执行的三个阶段和涉及方法做了详细说明:
 文章插图
文章插图- 以上两张图片的出处都是kent7306的文章《Hive UDAF开发详解》 , 地址:
- 上面两幅图将抽象方法和每个阶段的关系都梳理得很清晰了 , 接下来咱们开始编码;
- 如果您不想编码 , 可以在GitHub下载所有源码 , 地址和链接信息如下表所示:
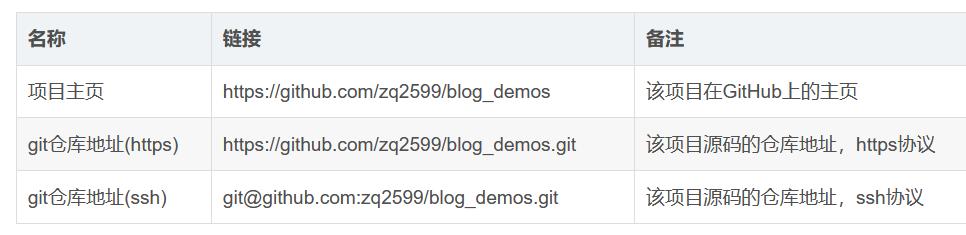 文章插图
文章插图- 这个git项目中有多个文件夹 , 本章的应用在hiveudf文件夹下 , 如下图红框所示:
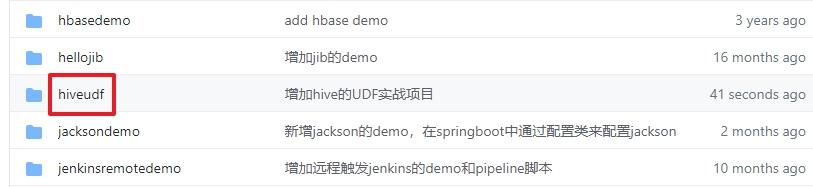 文章插图
文章插图UDAF开发步骤简述开发UDAF分为以下几步:
- 新建类FieldLengthAggregationBuffer , 用于保存中间结果 , 该类需继承AbstractAggregationBuffer;
- 新建类FieldLengthUDAFEvaluator , 用于实现四个阶段中会被调用的方法 , 该类需继承GenericUDAFEvaluator;
- 新建类FieldLength , 用于在hive中注册UDAF , 里面会实例化FieldLengthUDAFEvaluator , 该类需继承AbstractGenericUDAFResolver;
- 编译构建 , 得到jar;
- 在hive添加jar;
- 在hive注册函数;
开发
- 打开前文新建的hiveudf工程 , 新建FieldLengthAggregationBuffer.java , 这个类的作用是缓存中间计算结果 , 每次计算的结果都放入这里面 , 被传递给下个阶段 , 其成员变量value用来保存累加数据:
package com.bolingcavalry.hiveudf.udaf;import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;import org.apache.hadoop.hive.ql.util.JavaDataModel;public class FieldLengthAggregationBuffer extends GenericUDAFEvaluator.AbstractAggregationBuffer {private Integer value = http://kandian.youth.cn/index/0;public Integer getValue() {return value;}public void setValue(Integer value) {this.value = value;}public void add(int addValue) {synchronized (value) {value += addValue;}}/*** 合并值缓冲区大小 , 这里是用来保存字符串长度 , 因此设为4byte* @return*/@Overridepublic int estimate() {return JavaDataModel.PRIMITIVES1;}}
- 截图|笔记本截图快捷键是什么
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 每日|【每日idea 分享】12月1日:带朋友一起网上购物;线上笔记本应用程序
- 用于|用于半监督学习的图随机神经网络
- 复习|期末整理复习笔记?MHMO魅蒙iPad专用笔助提高效率
- 今日|“舜网”学习强国号今日上线 济南报业全媒体矩阵再添新成员
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 效果|这个让你相见恨晚的技巧,能让PPT排版更加有设计感,推荐学习
- 学习C语言的软件,就突然被我绿了?
- 学习python第二弹