模型|重点!11个重要的机器学习模型评估指标
全文共8139字 , 预计学习时长16分钟构建机器学习模型的想法应基于建设性的反馈原则 。 你可以构建模型 , 从指标得到反馈 , 不断改进 , 直到达到理想的准确度 。 评估指标能体现模型的运转情况 。 评估指标的一个重要作用在于能够区分众多模型的结果 。
很多分析师和数据科学家甚至都不愿意去检查其模型的鲁棒性 。 一旦完成了模型的构建 , 他们就会急忙将预测值应用到不可见的数据上 。 这种方法不正确 。
我们的目的不能是简单地构建一个预测模型 。 目的是关于创建和选择一个对样本以外数据也能做到高精度的模型 。 因此 , 在计算预测值之前 , 检查模型的准确性至关重要 。 文章插图
文章插图
在这个行业中 , 大家会考虑用不同类型的指标来评估模型 。 指标的选择完全取决于模型的类型和执行模型的计划 。
模型构建完成后 , 这11个指标将帮助评估模型的准确性 。 考虑到交叉验证的日益普及和重要性 , 本文中也提到了它的一些原理 。 文章插图
文章插图
预测模型的类型
说到预测模型 , 大家谈论的要么是回归模型(连续输出) , 要么是分类模型(离散输出或二进制输出) 。 每种模型中使用的评估指标都不同 。
在分类问题中 , 一般使用两种类型的算法(取决于其创建的输出类型):
1.类输出:SVM和KNN等算法创建类输出 。 例如 , 在二进制分类问题中 , 输出值将为0或1 。 但如今 , 有算法可以将这些类输出转换为概率输出 。 但是 , 统计圈并不是很乐意接受这些算法 。
2.概率输出:逻辑回归( Logistic Regression ) , 随机森林( Random Forest ) , 梯度递增( Gradient Boosting ) , Adaboost等算法会产生概率输出 。 将概率输出转换为类输出只是创建一个阈值概率的问题 。
在回归问题中 , 输出时不会出现这种不一致性 。 输出本来就是一直连续的 , 不需要进一步处理 。
例证
关于分类模型评估指标的讨论 , 笔者已在Kaggle平台上对BCI挑战做了预测 。 问题的解决方案超出了此处讨论的范围 。 但是 , 本文引用了训练集的最终预测 。 通过概率输出预测该问题 , 假设阈值为0.5的情况下 , 将概率输出转换为类输出 。文章插图
1. 混淆矩阵
混淆矩阵是一个N×N矩阵 , N是预测的类的数量 。 针对目前的问题 , 有N = 2 , 因此得到一个2×2的矩阵 。 你需要记住以下这些关于混淆矩阵的定义:
· 准确性:正确预测的结果占总预测值的比重
· 阳性预测值或查准率:预测结果是正例的所有结果中 , 正确模型预测的比例
· 阴性预测值:预测结果是负例的所有结果中 , 错误模型预测的比例 。
· 敏感度或查全率 :在真实值是正例的结果中 , 正确模型预测的比重 。
· 特异度:在真实值是负例的所有结果中 , 正确模型预测的比重 。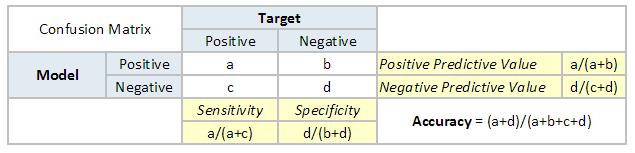 文章插图
文章插图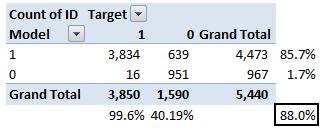 文章插图
文章插图
目前案例的准确率达到88% 。 从以上两个表中可以看出 , 阳性预测值很高 , 但阴性预测值很低 , 而敏感度和特异度一样 。 这主要由选择的阈值所造成 , 如果降低阈值 , 两对截然不同的数字将更接近 。
通常 , 大家关注上面定义的指标中的一项 。 例如 , 一家制药公司 , 更关心的是最小错误阳性诊断 。 因此 , 他们会更关注高特异度 。 另一方面 , 消耗模型会更注重敏感度 。 混淆矩阵通常仅用于类输出模型 。文章插图
2. F1分数
在上一节中 , 讨论了分类问题的查准率和查全率 , 也强调了在用例中选择查准率和查全率的重要性 。 如果对于一个用例 , 想要试图同时获得最佳查准率和查全率呢?F1-Score是分类问题查准率和查全率的调和平均值 。 其公式如下: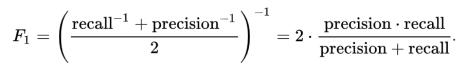 文章插图
文章插图
现在 , 一个显而易见的问题是 , 为什么采用调和平均值而不是算术平均值呢?这是因为调和平均值可以解决更多极值 。 通过一个例子来理解这一点 。 有一个二进制分类模型的结果如下:
查准率:0 , 查全率:1
这里 , 如果采用算术平均值 , 得到的结果是0.5 。 很明显 , 上面的结果是一个“傻子”分类器处理的 , 忽略了输入 , 仅将其预测的其中一个类作为输出 。 现在 , 如果要取调和平均值 , 得到的结果就会是0 , 这是准确的 , 因为这个模型对于所有的目的来说都是无用的 。
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 智慧|优酷大屏“酷喵”发布数字生活家庭战略,重点发力客厅场景
- 建筑|国产第一台掘进机模型亮相“2020长江·三峡建筑产业博览会”
- 家庭|优酷大屏“酷喵”发布数字生活家庭战略,重点发力客厅场景
- 「数据架构」TOGAF建模:概念数据模型图
- 五种IO模型详解
- 老年人助听器选配需重点注意哪些?
- 用模型再骗20亿美金?又一个造车界大忽悠被扒
- 头文件|阿里面试题 | Nginx 所使用的 epoll 模型是什么?