Google Meet 背景模糊功能
文 / Google研究院软件工程师 , Tingbo Hou--tt-darkmode-bgcolor: #1C1C1C;">译者 / Alpha
技术审校:斗鱼前端专家 , 王兴伟
原文 /
在人们的工作和生活中 , 视频会议变得越来越重要 。 我们可以通过增强隐私保护 , 或者添加有趣的视觉效果来改善视频体验 , 同时帮助人们将注意力集中在会议内容上 。 我们最近宣布的在Google Meet中模糊和替换背景的方法 , 就是为了实现这一目标而迈出的一小步 。
我们利用机器学习(ML)来更好地突出参与者 , 从而忽略他们周围的背景环境 。 尽管其他的解决方案需要安装额外的软件 , 但Meet的功能是由尖端的Web ML技术提供支持的 , 这些技术是用MediaPipe构建的 , 可以直接在你的浏览器中工作——不需要额外的步骤 。
开发这些功能 , 有一个关键目标 , 即它可以给几乎所有现代设备提供实时的浏览器内性能 , 通过XNNPACK和TFLite , 我们将高效的设备上ML模型、基于WebGL的效果渲染 , 还有基于Web的ML推理结合起来 , 进而实现了这一目标 。 文章插图
文章插图
背景模糊和背景替换 , 由网页端的 MediaPipe 提供支持 。
网络Web ML方案概述
Meet中的新功能是与MediaPipe一起开发的 , MediaPipe是谷歌的开源框架 , 用于为直播和流媒体提供跨平台的 , 可定制的ML解决方案 , 它还支持设备上实时性的手、虹膜和身体姿势追踪等ML解决方案 。
任何设备上解决方案的核心需求 , 都是实现高性能 。 为了实现这一点 , MediaPipe的Web工作流利用了WebAssembly , 这是一种专为网络浏览器设计的底层二进制代码格式 , 可以提高计算繁重任务的速度 。 在运行时 , 浏览器将WebAssembly指令转换为本机代码 , 执行速度比传统JavaScript代码快很多 。 此外 , Chrome84最近引入了对WebAssembly SIMD的支持 , 每条指令可以处理多个数据点 , 性能提升了2倍以上 。
首先 , 我们的解决方案通过将用户 , 和他们的背景进行分割(稍后将详细介绍我们的分割模型) , 来处理每个视频帧 , 使用ML推理来计算出一个低分辨率的蒙版 。 或者 , 我们还可以进一步细化蒙版 , 以使其与图像边界对齐 。 然后通过WebGL2使用蒙版来渲染视频 , 实现背景的模糊或替换 。 文章插图
文章插图
WebML Pipeline:所有计算繁重的操作都是用C++/OpenGL实现的 , 并通过WebAssembly在浏览器中运行 。
【Google Meet 背景模糊功能】在当前版本中 , 模型推理在客户端的CPU上执行 , 以实现低功耗和最大的设备覆盖范围 。 为了达到实时性能 , 我们设计了高效的ML模型 , 通过XNNPACK库加速推理 , XNNPACK库是第一个专门为新的WebAssembly SIMD规范设计的推理引擎 。 在XNNPACK和SIMD的加速下 , 该分割模型可以在Web上以实时速度运行 。
在MediaPipe灵活配置的支持下 , 背景模糊/替换解决方案可根据设备能力 , 调整其处理过程 。 在高端设备上 , 它运行完整的工作流 , 以提供最佳的视觉质量 , 而在低端设备上 , 通过使用轻量级的ML模型进行计算 , 并且绕过蒙版细化 , 它仍然可以保持较高的性能 。
分割模型细分
设备上的机器学习模型必须是超轻量级的 , 以实现快速推理、低功耗和较小的下载大小 。 对于在浏览器中运行的模型 , 输入分辨率会极大地影响处理的每一帧所需的浮点运算(FLOP)的数量 , 由此也必须很小 。 我们将图像下采样 , 得到较小的尺寸 , 然后再将其提供给模型 。 从低分辨率图像中 , 尽可能精确地恢复分割蒙版 , 这增加了模型设计的挑战 。
整个分割网络具有关于编码和解码的对称结构 , 而解码器块(浅绿色) , 也与编码块(浅蓝色)共享对称层结构 。 具体地说 , 在编码器和解码器模块中 , 都采用了应用有全局池化层技术的通道注意力机制 , 这有利于高效的CPU推理 。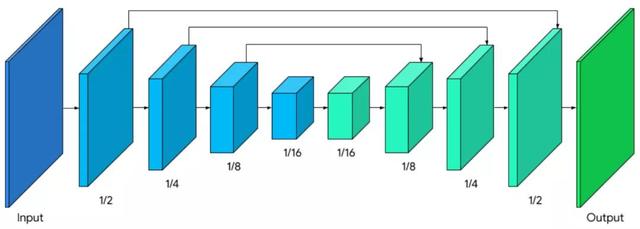 文章插图
文章插图
采用MobileNetV3编码器(浅蓝色)和对称解码器(浅绿色)的模型架构 。
我们修改MobileNetV3-Small为编码器 , 经过网络结构搜索的优化 , 以最低的资源需求 , 获得最佳的性能 。 为了减少50%的模型尺寸 , 我们使用Float16量化技术将模型导出到TFLite , 仅权重精度略有下降 , 但对质量没有明显的影响 。 得到的模型有193K参数 , 大小只有400KB 。
- Play|Google Play公布2020年度最佳应用和游戏排行榜
- 新闻记者|媒体融合背景下新闻记者如何转型
- 每天有超过10亿人使用Google搜索
- Google Play公布2020年度最佳应用和游戏排行榜
- 这个人工智能翻译网站,比Google翻译强太多了吧
- 做好|在新媒体营销背景下,如何做好产品定位?
- 微信/QQ聊天背景壁纸,嘿嘿嘿
- 华理|华理知识产权高峰论坛, 聚焦“新专利法背景下科创与知识产权保护”
- 标签|Google Chrome 标签页组自动创建功能现已推出
- 成立|如意云的成立背景及发展现状